17.03.1973|
|
0 Comment
Дифференциация а я 2 класс упражнения: Дифференциация гласных “А-Я” (2 класс VIII dslf)
Дифференциация гласных “А-Я” (2 класс VIII dslf)
ТЕМА: Дифференциация гласных звуков и букв А-Я
ЦЕЛИ:
Учебные: – формировать умение определять положение органов при произношении гласных звуков, различать данные звуки.
Коррекционные:
развивать речевую, мелкую, общую моторику;
развивать фонематическое восприятие;
совершенствовать звуковой анализ слов;
Воспитательные: – формирование самоконтроля.
ОБОРУДОВАНИЕ: предметные картинки (аист, апельсин, аквариум, якорь, ягоды, яблоко), картинки с изображением незаконченных печатных букв, карточка со словами для списывания, барх. бумага, погремушка, карточка с домашним заданием.
ХОД ЗАНЯТИЯ.
Подготовительный этап.
1. Артикуляционная гимнастика.
Упражнения для губ: улыбка, заборчик, трубочка, хоботок, чередование.
Упражнения для языка: лопатка, чашечка, иголочка.
Поднять широкий язык на верхнюю губу, опустить на нижнюю губу: «Часики», кончик языка к верхним бугоркам, почистить верхние зубы, кончик языка к верхним бугоркам, почистить нижние зубы.
Упражнения для нижней челюсти: опустить, поднять.
Введение в тему.
2. Беззвучная артикуляция.
3. «Что лишнее. Почему?» Язык, губы, рука.
ГОВОРИМ КРАСИВО, ВНЯТНО,
ЧТОБЫ БЫЛО ВСЕМ ПОНЯТНО!
Сообщение темы.4. Назвать гласные, которые «дружат» с твёрдыми согласными, с мягкими.
Мы повторили органы артикуляции. Сегодня будем определять положение при произношении гласных звуков А-Я.
Работа по теме занятия.
5. Узнай буквы, дорисуй их, отгадай тему занятия.
5.1. Преврати звуки в буквы и запиши их письменно.
5.2. Выложи строчные буквы на бархатной бумаге.
Работа с картинками. Называние предмета и первой гласной.
5.3. Уточнение артикуляции звуков [А], [Я] .
Пальчиковая гимнастика:
Мышка в норку пробралась
На замочек заперлась
В дырочки она глядит,
На заборе кот сидит.
5.4 Поймай звук: если слышишь звук
Тя, ря, ма, та, дя, ла, ка, ня.
5.5 Работа в тетради: Списывание слов с гласной буквой А в 1 столбик, слова с гласной буквой Я во 2 столбик, буква А – красным цветом, а букву Я – зелёным (змея, рыба, луна, ямы).
5.7 Повторение слоговых цепочек:
Прослушай, запомни и повтори ряды слогов.
Та – тя – та ла – ля – ла бя –ба-бя
Тя- та- тя ля –ла – ля ба –бя –ба
Подведение итогов.
Дыхательная гимнастика.
Домашнее задание.
А дома ты обведи и раскрась весёлую картинку, найди и выпиши слова с гласными А, Я, выделяя их соответствующими цветами.
Урок подготовила и провела
Учитель – логопед I категории
М. А. Лужанская
Конспект “Дифференциация А – Я” (2 класс)
Конспект логопедического занятия «Дифференциация а – я»
Дата:
Тема:
Дифференциация гласных а-я
Цель:
учить дифференцировать буквы а-я; продолжать учить сравнивать слова по смыслу и по написанию; развивать звуковой и слоговой анализ и синтез; развивать внимание, память, мышление.
Оборудование:
Буквы А-Я; мяч, карточки с заданиями, тетради.
Ход занятия:
1 часть. Орг.момент:
отгадайте слово по действию, определите гласные:
Хрюкает, чавкает – свинья
Плодоносит, растет – яблоко
Прыгает, растет – заяц
Какие были слова? Что лишнее, почему?
2 часть. Работа над материалом:
Допишите буквы, чтобы получилось слово. ( в тетрадях у детей написано слово заяц, мяч)
Какие буквы дописали? Что мы знаем о букве Я? В каком слове Я – служит для смягчения согласных?
В каком слове Я – хитрая?
Сегодня, мы еще раз поговорим о парных гласных а-я.
Послушайте слоги:
Ма, на, са, ка, ла, па, ра, та, фа, ва
Мя, ня, ся, кя, ля, пя, ря, та, фя, вя
Скажите какой гласный вы слышите?
Как звучат гласные, которые вы слышали в начале и потом?
Какой гласный влияет на смягчения согласных?
Сравните слова МАЛ – МЯЛ, РАД – РЯД, ЗАВАЛ – ЗАВЯЛ, САД –СЯДЬ – по смыслу и по написанию. Какими буквами различаются эти слова?
Какими буквами различаются эти слова?
Развитие фонематического восприятия. (с мячом).
Прослушайте, запомните и повторите ряды слогов.
Та – тя – та ма – мя – ма бя –ба-бя
Тя-та-т я мя –ма – мя ба –бя –ба
Ра – ря – ра – ря
Ря – ра – ря – ра
Работа по карточки
Прочитайте слова, вставляя пропущенную букву а-я.
Б….к, р…д, м….к, вр…ч, с…дь, м…ч, в….з, т…з, м….со, к….ша, д……дя, гр….ды, шл….па, вр….ги.
Проверка задания.
Работа в тетрадях.
Спишите слова, деля их на слоги, подчеркивая буквы а-я ручками разного цвета.
Доска, марка, змея, пояс, армия, братья, клякса, аист, вялая, земная.
Чтение текста. ( карточка) .
Наша Зоя мала. Наташа сама рыла ямку. Маша взяла мяч. Боря искал ягоды. Люба мяла глину. Алла, сядь и сама читай книгу. Алла мала, да умна.
Выпишите слова с буквой –а – в один столбик; с буквой –я – во второй; с буквами – а- я – в третий столбик.
Проверка задания.
Итог занятия:
Какие буквы мы с вами учились различать на письме?
Что дает буква –я -?
Когда она бывает хитрая?
Прочитайте слова, вставляя пропущенную букву а-я.Б….к, р…д, м….к, вр…ч, с…дь, м…ч, в….з, т…з, м….со, к….ша, д……дя, гр….ды, шл….па, вр….ги.
Прочитайте слова, вставляя пропущенную букву а-я.
Б….к, р…д, м….к, вр…ч, с…дь, м…ч, в….з, т…з, м….со, к….ша, д……дя, гр….ды, шл….па, вр….ги.
Прочитайте слова, вставляя пропущенную букву а-я.
Б….к, р…д, м….к, вр…ч, с…дь, м…ч, в….з, т…з, м….со, к….ша, д……дя, гр….ды, шл….па, вр….ги.
Прочитайте слова, вставляя пропущенную букву а-я.
Б….к, р…д, м….к, вр…ч, с…дь, м…ч, в….з, т…з, м….со, к….ша, д……дя, гр….ды, шл….па, вр….ги.
Работа в тетрадях.
Спишите слова, деля их на слоги, подчеркивая буквы а-я ручками разного цвета.
Доска, марка, змея, пояс, армия, братья, клякса, аист, вялая, земная.
Работа в тетрадях.
Спишите слова, деля их на слоги, подчеркивая буквы а-я ручками разного цвета.
Доска, марка, змея, пояс, армия, братья, клякса, аист, вялая, земная.
Работа в тетрадях.
Спишите слова, деля их на слоги, подчеркивая буквы а-я ручками разного цвета.
Доска, марка, змея, пояс, армия, братья, клякса, аист, вялая, земная.
Работа в тетрадях.
Спишите слова, деля их на слоги, подчеркивая буквы а-я ручками разного цвета.
Доска, марка, змея, пояс, армия, братья, клякса, аист, вялая, земная.
Чтение текста. ( карточка) .
Наша Зоя мала. Наташа сама рыла ямку. Маша взяла мяч. Боря искал ягоды. Люба мяла глину. Алла, сядь и сама читай книгу. Алла мала, да умна.
Выпишите слова с буквой –а – в один столбик; с буквой –я – во второй; с буквами – а- я – в третий столбик.
Чтение текста. ( карточка) .
Наша Зоя мала. Наташа сама рыла ямку. Маша взяла мяч. Боря искал ягоды. Люба мяла глину. Алла, сядь и сама читай книгу.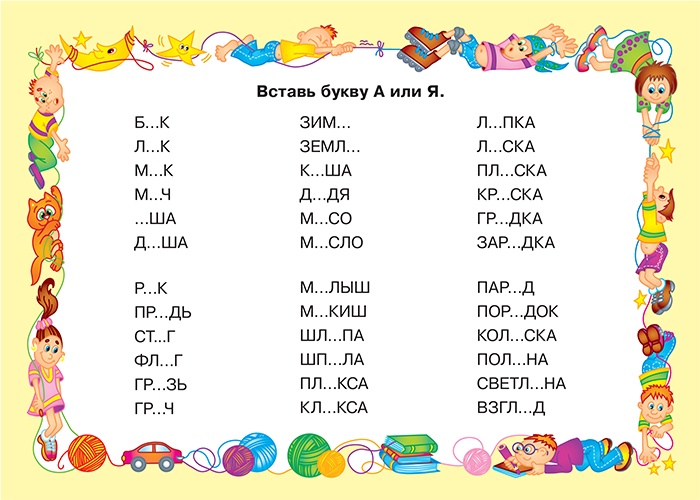
Выпишите слова с буквой –а – в один столбик; с буквой –я – во второй; с буквами – а- я – в третий столбик.
Чтение текста. ( карточка) .
Наша Зоя мала. Наташа сама рыла ямку. Маша взяла мяч. Боря искал ягоды. Люба мяла глину. Алла, сядь и сама читай книгу. Алла мала, да умна.
Выпишите слова с буквой –а – в один столбик; с буквой –я – во второй; с буквами – а- я – в третий столбик.
Чтение текста. ( карточка) .
Наша Зоя мала. Наташа сама рыла ямку. Маша взяла мяч. Боря искал ягоды. Люба мяла глину. Алла, сядь и сама читай книгу. Алла мала, да умна.
Выпишите слова с буквой –а – в один столбик; с буквой –я – во второй; с буквами – а- я – в третий столбик.
Чтение текста. ( карточка) .
Наша Зоя мала. Наташа сама рыла ямку. Маша взяла мяч. Боря искал ягоды. Люба мяла глину. Алла, сядь и сама читай книгу. Алла мала, да умна.
Выпишите слова с буквой –а – в один столбик; с буквой –я – во второй; с буквами – а- я – в третий столбик.
Чтение текста. ( карточка) .
Наша Зоя мала. Наташа сама рыла ямку. Маша взяла мяч. Боря искал ягоды. Люба мяла глину. Алла, сядь и сама читай книгу. Алла мала, да умна.
Выпишите слова с буквой –а – в один столбик; с буквой –я – во второй; с буквами – а- я – в третий столбик.
Дифференциация гласных и согласных звуков и букв.
Логопедическое занятие во 2 классе.
Тема: Дифференциация гласных и согласных звуков и букв.
Лексическая тема: Осень
Грамматическая: Гласные и согласные звуки и буквы.
Цель: формировать навык различения гласных и согласных звуков и букв.
Задачи:
Коррекционно-образовательные:
Закреплять навыки различения гласных и согласных звуков.
Закреплять знания о характеристиках звуков.
Развивать навыки звукобуквенного анализа слов.
Совершенствовать буквенный гнозис и праксис.
Развивать навыки звукового анализа и синтеза.
Развивать плавный выдох, подвижность органов артикуляционного аппарата.
Формировать навыки словообразования.
формировать и расширять семантическое поле слова «Осень»;
Коррекционно-развивающие:
Совершенствовать фонематическое восприятие; артикуляционную моторику, мимические мышцы лица;
Развивать плавный выдох, подвижность органов артикуляционного аппарата.
Систематизировать знания об осени и осенних явлениях;
Активизировать словарь по данной теме.
Воспитательные:
Воспитывать положительную мотивацию к занятиям.
Воспитывать усидчивость, аккуратность, организованность, дисциплинированность.
3. Воспитывать интерес к занятиям с логопедом.
4.Расширять представления об окружающем мире и воспитывать бережное отношение к природе.
Оборудование: листья деревьев, картина «Осень», муляжи овощей , предметные картинки, плакат «Сентябрь», карточки со словами , карточки с набором букв, карточки с письменными заданиями, компьютер.
Ход:
I. Организационный момент.
Здравствуйте, встаньте ровно рядом со своим местом!
Представьтесь, садитесь.
Сядьте ровно, спина прямая, руки на парте.
Развитие воображения, актуализация словаря по лексической теме.
Отгадайте загадку.
Дни стали короче,
Длиннее стали ночи.
Урожай собирают,
Когда это бывает? (Осенью)
– Ребята, сегодня поговорим про осень.
II. Развитие моторики. Работа по развитию дыхания.
Работа по развитию дыхания.
1. Развитие мимических мышц.
-Вот после осеннего дождя выглянуло солнышко, и вы улыбнулись, обрадовались.
-Но вдруг набежала тучка, и вы нахмурились, огорчились.
-Но ветер унес тучки, и вы снова улыбнулись.
2.Упражнения для развития мелкой моторики.
Упражнение «Дождик»
3. Артикуляционная гимнастика.
1. Упражнения на развитие длинного плавного выдоха.
– Как дует ветер?
– Сдуть листики с руки.
2. Упражнения на развитие подвижности органов артикуляции.
– «Язычок вышел погулять. Посмотрел на небо, на травку, влево, вправо. Удивился: «Ах! Как красиво вокруг!» Улыбнулся язычок (губы в улыбке), «Ух! Хорошо» (губы трубочкой)»
III.Актуализация знаний учащихся. (Выставляется картинка «Осень»)
Упражнения по развитию лексико-грамматической стороны речи.
| Приходит (что?)-… Плывут (что?)-… Дует (что?)-… Вянут (что?)-… | Желтеют (что?)-… Улетают (кто?)-… Готовятся к зиме (кто?)-… Моросит (что?)- |
-«Подбери признак»
Листья осенью (какие?)-…
Дождь осенью (какой?)-…
Погода осенью (какая?)-…
– Игра «Один – много»
Дождь – дожди, день – …., ветер – …,
туча – …, дерево – …, лист – …,
трава – …, гриб – ….
IV. Сообщение темы урока.
– Сегодня мы будем ЗАКРЕПЛЯТЬ умения различать гласные и согласные звуки .
V. Изучение нового материала.
1) Отличия гласных и согласных звуков.
– Перечислим все отличия гласных и согласных звуков (пособие на доске).
| Гласные | Согласные |
| можно петь | нельзя петь |
| нет преграды | преграда (рис. губы, зубы, язык) |
| голос | шум шум+голос |
2) Развитие долговременной памяти.
– Разучим стихотворение.
Если гласный говорят –
Нет во рту у нас преград.
А если согласный сказать надо
Во рту возникает преграда.
На письме звуки обозначаются буквами.
-Какими могут быть гласные звуки? Согласные?
-Сколько гласных букв?
-Cколько согласных букв?
3) Развитие фонематического восприятия.
Игра «Выбери картинку»
– Назовите предметы на картинках (10 предметов).
– Назовите только те, в названиях которых вы слышите звук
А – 8 картинок
О – 2 карт.( ПАЛЬТО, АВТОБУС)
У – 5 карт.(ДУБ, ЛУК, УЛИТКА,АРБУЗ, АВТОБУС)
Ы – 2 карт. (РЫБА, ТЫКВА).
Игра «Собери картинки в коробочки» – работа на печатных листах.
Игра «Какая картинка лишняя в каждом ряду?» – – работа на печатных листах.
4) Развитие буквенного анализа, зрительного внимания.
Карточки с буквами.
– Кто самый зоркий?
– Закрасьте все гласные буквы красным карандашом. Если все правильно выполните – что-то получится.
– Получается сердечко. Дорисуйте (обведите сердечко).
Обводят все гласные красным.
К М Л А У Ш О Ы Ц Ф В Т
Н Г И П Т Э Д Л У Ш З Д
Ф В П У Р Л Ж Щ Ы Д Ч С Н
Т Б Н О Х К М А Х П Г С
Д Л Н Ф Т Э М Г П К Щ
VI. Динамическая пауза.
Листья осенние тихо кружатся, (кружатся на носочках)
Листья нам под ноги тихо ложатся, (приседают)
И под ногами шуршат, шелестят. (машут руками влево-вправо)
Будто опять закружиться хотят. (кружатся)
(кружатся)
VII. Работа над закреплением гласных и согласных.
Прочитайте слова, назовите (согласные). Посчитайте буквы, напишите количество. Учитель даёт образец. (Дети выходят к доске)
Слова: дождь, осень, листья, ветер, сентябрь.
VIII. Работа над словообразованием.
Отгадайте, о чём мы будем говорить дальше.
Загадка.
Растут – зеленеют.
Упадут – пожелтеют.
Полежат – почернеют.
– Правильно, ребята, это листья.
– Назовите ласково «лист». (Листочек)
– Как называется явление, когда падают листья? (Листопад)
– Узнайте, какое слово я загадала (логопед по звукам произносит слово «л,и,с,т,и,к».
Логопед показывает листья с различных деревьев и кустарников:
берёза, осина, рябина, клён, ива, дуб.
– С какого дерева лист? (с берёзы)
– Значит, какой это лист? (берёзовый лист).
Далее проводится аналогичная работа и с листьями других деревьев: клён – кленовый, рябина – рябиновый, ива – ивовый, дуб – дубовый и т.д.
Логопед выставляет листья, дети внимательно разглядывают их. Затем закрывают глаза, а логопед убирает один лист.
– Какого листа не стало?
IX.Развитие буквенного праксиса, гнозиса, фонематических представлений.
Игра «Волшебный мешочек» или «Чудесная корзина».
– В «Волшебном мешочке» перемешались муляжи овощей.
Подходите по одному. Доставай овощ, ощупывай, узнавай.
Называем первый звук, даём ему полную характеристику?
X.Подведение итогов урока.
– О каком времени года говорили?
– Какие звуки мы сегодня учились различать?
– Чем они различаются?
(Можно дать дом. задание на печатных листочках).
XI. Оценка деятельности детей. Рефлексия.
– Подойдите все к лесенке успеха.
– Соберите пазл «ОСЕНЬ И Смешарики».
– Молодцы! Хорошо поработали. Спасибо. Наведите порядок на столах.
До свидания.
ЛОГОПЕД.РУ: Дифференциация гласных звуков Ы–И. Урок логопедии во втором классе.
“лягушка”, “Заборчик”, “блинчик”, “Ветерок” “Змейка”
Прочитать стихотворение С. Погореловского “Ох, и не порядки в Мишкиной тетрадке”.
– Что глядишь, корова,
Строго и сурово?
– Мишка-лодырь через “а”
Написал “карова”
Напишите вы
Мишка через “ы”,
Проучите Мишку –
Превратите в мышку.
Кошка мышку хвать!
Будет лодырь знать.
– Выделить слова до и после замены гласной, сравнить слова по смыслу и написанию
(“Мишка” – имя мальчика, “ мышка” – дикое животное )
Предлагаю детям произнести звук “и” и посмотреть в индивидуальные зеркала в каком положении находятся язык и губы? (язык у нижних зубов, губы “улыбаются”).
Затем произносится звук ы. (при произнесении этого звука язык оттягивается от зубов).
– Показать соответствующие буквы.
Характеристика звуков:
Ы – гласная первого ряда
И – гласная второго ряда. (функция гласных второго ряда – смягчать впереди стоящую согласную)
 Упражнения на дифференциацию звуков Ы – И в слоге
Упражнения на дифференциацию звуков Ы – И в слогеИгра с мячом – “назови наоборот”:
Мы – (ми)
Бы – ( би)
Вы – ( ви)
Лы – (ли)
Зы – (зи)
Ды – (ди)
Был – (бил)
Мыл – (мил)
Выл – (вил)
Пыл – (пил)
5. Поднять букву, обозначающую звучащий звук
в слоге:
Пы, ти, ри, бы, кы, ди, би, ми, сы, ты, мы, ки, ды, пи.
в слове:
липа, сыр, кит, рыба, губы, язык, руки.
Сы-сы-си, ри-ры-ры, ды-ди-ды.
Пальцы – дружная семья,
Друг без друга им нельзя
Вот большой, а это – средний,
Безымянный
И последний наш мизинец молодец
Указательный забыли,
Чтобы пальцы дружно жили
Будем их соединять
Упражненье выполнять.
Дифференциация а—я. Тренировочные упражнения
Дифференциация гласных первого и второго ряда Конспект занятия
Т е м а. Дифференциация гласных первого и второго ряда. Цель. Учить детей различать гласные ы – и устно и на письме.
Оборудование. Текст стихотворения С. Погореловского «Ох и неполадки в Мишкиной тетрадке», таблица с гласными первого и второго ряда
Ход за ня т и я
I. Организационный момент.
Логопед предлагает учащимся вспомнить и назвать гласные первого и второго ряда.
II. Повторение ранее пройденного материала. Логопед предлагает учащимся вспомнить, как образовываются гласные второго рода. Вывешивает таблицу с гласными первого и второго ряда.
| а | о | у | э | ы |
| я | ё | ю | е | и |
Предлагает сравнить пары гласных:а –я, о – ё,у – ю,з – е,ы –и.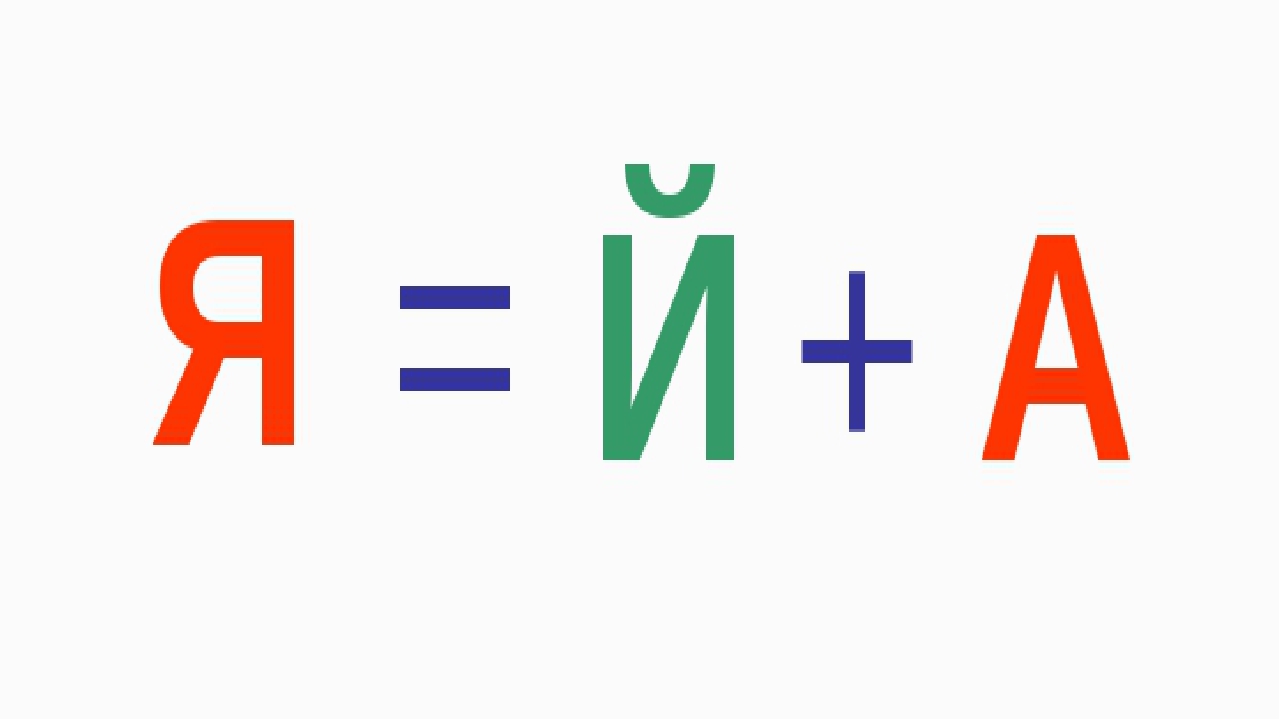 Выявляется сходство этих пар по артикуляции и различие по написанию.
Выявляется сходство этих пар по артикуляции и различие по написанию.
«Эти гласные называются парными. Чтобы не путать их при письме, будем учиться их различать», – говорит логопед.
III. Работа со стихотворением.
Логопед читает стихотворение.
-Что глядишь, корова, Мишку через «ы»,
Строго и сурово? Проучите Мишку –
– Мишка-лодырь через «а» Превратите в мышку.
Написал корова. Кошка мышку хвать!
Напишите вы Будет лодырь знать.
Логопед предлагает детям сравнить слова Мишка и мышка по смыслу и написанию. Пишет на доске эти слова. Спрашивает, какими буквами отличается написание этих слов.
IV. Дифференциация ы – и в слогах.
1. Прослушайте слоги. Скажите, какой гласный вы слышите.
а) Пы. ты, мы, сы, ры, ды, бы, кы;
б) пи, ти, ми, си. ри.ди. би, ки
«Как произносятся согласные, которые вы слышали сначала и потом? (Твердо, мягко)
Какой звук здесь обозначает мягкость согласных?» – спрашивает логопед.
2. Повторите слоги за логопедом.
Пы – пи – пи, ти – ты – ти сы – сы – си ри -ры -ры ды – ди – ды.
3. Запишите слоги в две строчки: с ы – в первую, с и – во вторую.
Мы, си, сы, ми, ры, ри, ти, ты, кы, ки, ли, пи, пы, лы.
Задание 4. Закончите слова, вставив слоги, данные в скобках.
Гри…(бы), ли…(пы), ле…(пи), бо…(бы), ру…(ки), ры…(бы), ла…(пы), но…(ги), кни…(ги), со…(вы), ке…(ды), бе…(ги), кед…(ры), ко…(ты), ка…(ти).
V. Итог занятия.
Логопед задает вопрос: «Какие звуки и буквы мы учились сегодня различать?»
Тренировочные упражнения
Задание 1. Вставьте пропущенную букву ы или и. Запишите слова. Прочитайте их.
Р…с, м…с, м…р, с…р, к…т, р…сь, б…т, м…ло, л…па, Л…да, к…но, Р…та, с…ро, с…ла, м…л…, в…л…, в…л…,
л…с…, р…л…, п…л…, п…… .
Задание 2. Закончите слова, дописав букву и или и.
Ног. .., стол…, книг…, мак…, сыр…, лом…, шар…, сан…, бус…, кур…, сол…, сор… .
.., стол…, книг…, мак…, сыр…, лом…, шар…, сан…, бус…, кур…, сол…, сор… .
Задание 3. Измените слова по образцу. Назовите в получившихся словах последний слог, затем последнюю букву.
Образец: сад – сады, ды, ы. ‘
Коза – …, сова -…, муха – …, игра – …. оса – …, роза – …. лимон -…, сапог – …, собака – …, стакан- …, куст – …, рысь – …, корабль – …, стол – …, куча – … .
Задание 4. Спишите слова, деля их на слоги. Подчеркните слоги с ы, и разными карандашами.
Горы, мухи, кино, рыба, вари, сори, комары, фонари, сухари, рыбаки, рынки, киты, рыбки, рыбешки.
Задание 5. Запишите слова графически, напишитеы, ж.Логопед называет слово, учащиеся изображают его графически, учитывая количество слогов, над соответствующим слогом пишут буквуы,
илии.)
Соки, мыло, гуси, сыро, соты, вилы, куски, кусты, марки, карты, козлы, сапоги, рыбаки, листики, вагоны, сухари, узоры, уроки, музыка, пузыри, моторы.
Задание 6. Составьте слова с буквамиы, и. Сравните эти слова по смыслу и звучанию. Составьте устно предложение с каждым словом:
Ы ы ы ы ы
Задание 7. Спишите слова, подчеркнитеы, и разными карандашами. Объясните, почему после букв ж, ш написали букву и (вспомните правило).
Мыши, камыши, шина, лыжи, ножи, жиры, машины, тушил, галоши, решил, ширина, выжили, рыжики, лопухи, пружины, тишина, вышина, выжигали, вышивали.
Задание 8. Прочитайте предложения. Выпишите слова с буквой ы в один столбик, си – в другой, с буквами ы и и,- в третий.
У папы пила. Рита купила мыло. У Тани болят зубы. У Нины бусы. Из трубы идет дым. В саду растут сливы. В лесу сыро. У машины новые шины. У Миши ландыши.
Мила и мыло.
Не любила Мила мыла.Но не ныла Мила. Мама Милу с мылом мыла. Мила – молодчина.
Задание 9. Словарные диктанты.
Дым, мил, мыло, рыба, коровы, сами, уроки, были, было, пила, грибы, волки, лисы, кусты, зайцы, медведи, ковры, крабы, пруды, этажи, малыши, мыши, жили-были, уши, рыжики, комары, тишина, пружина, лужи, крыши, стрижи, виражи.
Объяснить слово: виражи.
Дифференциация а-я. Тренировочные упражнения
Задание 1. Прослушайте слоги. Скажите, какой гласный вы слышите
Логопедическое занятие по теме “Дифференциация гласных О-А в слогах, словах и предложениях”. 1-й класс
Класс: 1.
Тема: Дифференциация гласных О-А в слогах, словах и предложениях.
Цель: создать необходимые условия, при которых обучающиеся научатся различать гласные звуки [а-о] на слух и буквы «А», «О» на письме.
Задачи:
Коррекционно-образовательные
- уточнять и закреплять знания обучающихся о гласных звуках;
- учить дифференцировать гласные звуки А-О по их артикуляционным, акустическим и графическим признакам в слогах, словах, предложении;
Коррекционно-развивающие
- развивать навыки звукового анализа и синтеза;
- развивать общую и мелкую моторику;
- закрепить навыки пространственной ориентировки;
Воспитательные
- воспитывать языковую наблюдательность, внимание к речи своей и окружающих;
- формировать положительную учебную мотивацию.

Оборудование: презентация, мяч, разрезные картинки, индивидуальные карточки, индивидуальные зеркала.
Форма организации занятий: групповое логопедическое занятие.
Ход занятия 1. Организационный момент.Психоэтюд «Улыбнись»
Собрались все дети в круг, (логопед и дети встают в круг)
Я-твой друг, и ты-мой друг! (логопед показывает рукой на себя, потом на детей)
Крепко за руки возьмемся (беремся за руки)
И друг другу улыбнемся! (улыбаемся друг другу)
– Первым займет свое место, кто узнает звук по моим губам: (А, О, У, А)
– Какие звуки вы назвали?
– Какие гласные вы еще знаете?
– Соберите разрезные картинки, и вы узнаете, с какими гласными звуками мы будем работать на занятии.
Картинки: (слон, коза, баран, лось)
2. Основная часть занятия
Основная часть занятия
1) Объявление темы занятия.
– Назвать картинку, выделить гласные звуки.
– Какие гласные повторяются? (А-О)
– Где можно встретить всех этих животных вместе? ( В зоопарке)
– Как вы думаете, какая тема нашего занятия?
– Сегодня мы будем различать гласные звуки О-А в слогах и словах, предложениях. И совершим небольшую прогулку в зоопарк. Слайд №2
2) Анализ артикуляции гласных звуков А-О
Слайд №3
Работа с зеркалами
– Давайте сравним артикуляцию звука А и О, чем они отличаются и чем похожи?
А – Рот широко открыт, язык лежит у нижних зубов. Схема – кружок.
О – Губы округлены и слегка вытянуты вперед. Схема – овал.
3) Дыхательная гимнастика.
– Вы узнали, что идете в зоопарк и очень обрадовались, давайте покажем это через упражнение.
Вдох через нос на выдохе длительно произносим звук АААААА – радостно
Вдох через нос на выдохе длительно произносим звук ОООООО – испуганно
4) Развитие фонематического восприятия.
– До того как зайдем в зоопарк давайте проверим вашу внимательность.
Игра «Топ-Хлоп» на звук А– топ ножкой, на звук О –хлоп в ладоши.
А-О-АА-О-АМ-МО-ТО-ОП-АС ЛОСЬ, КАБАН, СЛОН, ЕНОТ, БАРСУК
5) Развитие фонематического анализа и синтеза.
– Итак, вы доказали, что очень внимательные. Животные приготовили вам задание: распределите их в две группы Слайд №4
Упражнение: распределить картинки животных в две группы (ЖИРАФ, ЛИСА, КАБАН, ВОЛК, СЛОН, НОСОРОГ, БАРАН, ЛОСЬ)
– Назовите животных со звуком А – барсук, лиса, кабан.
– Назовите животных со звуком О – волк, слон.
– В названии какого животного слышим звуки О-А? ( носорог).
6) Работа над буками О-А. Уточнение элементов строчных букв а и о. Дифференциация этих букв.
– Звуки вы хорошо слышите и различаете. А буквы хорошо различаете?
– Скажите, чем отличаются буквы от звуков? (Буквы мы видим и пишем, а звуки слышим и говорим).
– Из каких элементов состоит строчная буква О? А? Слайд №5
Педагог показывает карточки с прописными строчными буквами А и О.
(Буква О состоит из одного элемента – овала.
Буква А состоит из двух элементов – овала и наклонной линии с закруглением внизу вправо).
– Какой элемент у этих букв одинаковый? (Овал).
– Чем отличаются эти буквы? (Наклонной линией с закруглением внизу вправо. У буквы О ее нет, а у буквы А он есть).
7) Пальчиковая гимнастика
Это звери
У зверей четыре лапы (поднимаем и опускаем 4 пальца на обеих руках).
Когти могут поцарапать (пальцы двигаются как коготки).
Не лицо у них, а морда (соединить пальцы двух рук, образовав шарик, по очереди разъединять пальцы, опуская их вниз).
Хвост, усы и носик мокрый (волнообразные движения рукой, «рисуем» усы, круговые движения пальцем по кончику носа).
И, конечно, ушки (растираем ладонями уши)
Только на макушке (массажируем две точки на темени).
8) Корректурная проба. Работа на индивидуальных карточках.
Обвести букву А – в квадратик, О – в треугольник
– Посчитайте сколько букв а в 1строчке?
– Посчитайте сколько букв о во второй строчке?
9) Слоговой анализ.
Игра: «Определи место животного» Слайд №6
Животные предлагают вам узнать кто, за кем стоит, для этого вам нужно разделить названия животных на слоги и определить место звуков О-А (КАБАН, ВОЛК, ЛИСА, СЛОН, ЖИРАФ)
Первым стоит животное в названии, которого 2 слога и две гласные а. (кабан)
После кабана стоит животное в названии которого 1 слог, звук О находится после звука В. (волк)
Третьим стоит животное в названии которого 2 слога, звук А находится после звука С (лиса)
После лисы стоит животное в названии которого 1 слог, звук О стоит между звуками Л, Н (слон).
Ну и последним стоит животное в названии которого 2 слога, звук а во втором слоге (жираф).
– Молодцы, ребята. Вы большинство животных заняли свои места, но не все. Носорог приготовила вам следующее задание.
Физминутка. Игра с мячом «Назови детенышей животных»
У льва – львята
У тигра –
У лисы –
У козы –
У волка –
У слона – и т.д.
10) Закрепление изученного материала.
Игра «Волшебный мешок» нащупать букву, назвать ее и достать из мешочка.
Буквы: (Н, О, С, О, Р, О, Г)
– Соберите из данных букв слово. Слайд №7
– Прочитайте слово и найдите слова, которые прячутся в этом слове.
– Из каких двух слов состоит слово носорог?
– Это слово состоит из двух слов: нос, рог, о – соединительная гласная. Такие слова называются сложными.
– Какое еще сложное слово нам встретилось на занятии? (Зоопарк).
11) Образование притяжательных прилагательных.
Игра: «Раздай «хвосты» их владельцам» Слайд №8
Соединить подходящие картинки друг с другом и рассказать, комы отдал хвост. Образец: «Лисий хвост я отдал лисе…»
12) Работа над предложением.
– Ребята, животные придумали предложения, послушайте внимательно, все ли правильно?
Серый волк живет в Африке.
Слон охотится на зайца.
У жирафа короткая шея.
У лисы колючий хвост.
– Молодцы. А теперь давайте нарисуем схему к предложению, которое я продиктую и найдем буквы о-а в этом предложении.
Слон живёт в Африке. Слайд №9
3. Заключительная часть.– Ребята, какие гласные звуки мы с вами различали?
Игра «Да-нет».
– Звук а – согласный? (нет)
– Звук о – гласный? (да).
– У буквы а – два элемента? (да)
– Буква о – состоит из трех элементов? (нет)
– Спасибо, за ваше старание. До свидания.
До свидания.
Мы покидаем зоопарк, в знак благодарности звери дарят вам свои изображения (наклейки).
Карточки по дифференциации звуков и букв близких по акустико-артикуляторному сходству. Серия «Звонкие и глухие парные согласные Б-П».
КАРТОЧКИ по дифференциации звуков и букв близких по акустико-артикуляторному сходству Серия «Звонкие и глухие парные согласные Б-П» Автор-разработчик: учитель-логопед первой квалификационной категории МАОУ СОШ № 14 им. А. Ф. Лебедева г. Томска САПЕГИНА Е. С. Томск 2016г
Актуальность и новизна пособия
На сегодняшний день существуют различные авторские методические и дидактические разработки, направленные на дифференциацию сходных звуков и букв русского языка. Такие известные авторы как Е. В. Мазанова, Л. Н. Ефименкова, И. Н, Садовникова, Р. И. Лалаева и другие, создали хорошую базу рекомендаций и заданий, которые используют логопеды и дефектологи в своей работе. Обычно данные пособия содержат в себе несколько упражнений, направленных на дифференциацию определенных звуков и букв, тренировку с помощью устных и письменных заданий. На любых логопедических занятиях, в том числе и по дифференциации фонем и графем, специалист всегда решает множество задач, для реализации которых важно подбирать достаточно интересные многофункциональные упражнения и задания. Кроме того, тематические планирования, чаще всего, содержат требования к лексической теме занятий и строению материала от простого к сложному. Необходимость многофункциональности предъявляемых заданий, предполагает наличие у логопедов соответствующей дидактической базы (готовых карточек, пособий, конспектов занятий и т.д.)
Предлагаем вашему вниманию набор готовых карточек, рассчитанных на детей младшего школьного возраста с нарушениями речи первичного и вторичного характера. Данная серия карточек разработана для обучения дифференциации звонких и глухих парных согласных П-Б. Пособие рекомендовано учителям-логопедам и дефектологам школ, а также педагогам и родителям, сочетает в себе традиционные подходы коррекционно-развивающего обучения и многофункциональность заданий.
На любых логопедических занятиях, в том числе и по дифференциации фонем и графем, специалист всегда решает множество задач, для реализации которых важно подбирать достаточно интересные многофункциональные упражнения и задания. Кроме того, тематические планирования, чаще всего, содержат требования к лексической теме занятий и строению материала от простого к сложному. Необходимость многофункциональности предъявляемых заданий, предполагает наличие у логопедов соответствующей дидактической базы (готовых карточек, пособий, конспектов занятий и т.д.)
Предлагаем вашему вниманию набор готовых карточек, рассчитанных на детей младшего школьного возраста с нарушениями речи первичного и вторичного характера. Данная серия карточек разработана для обучения дифференциации звонких и глухих парных согласных П-Б. Пособие рекомендовано учителям-логопедам и дефектологам школ, а также педагогам и родителям, сочетает в себе традиционные подходы коррекционно-развивающего обучения и многофункциональность заданий. Разработка может использоваться как на занятиях, так и в качестве домашних заданий по закреплению тем.
Разработка может использоваться как на занятиях, так и в качестве домашних заданий по закреплению тем.
Цель пособия – создание многофункциональных заданий и упражнений в виде карточек по дифференциации звуков и букв, имеющих акустико-артикуляторное сходство. Задачи пособия: Развивать способность дифференцировать сходные звуки и буквы русского языка. Развивать навыки языкового анализа и синтеза. Развивать умение выделять ударение в слове. Развивать связную речь. Обогащать и актуализировать словарный запас детей. Развивать память, внимание и мышление.
Методические рекомендации по использованию пособия
Данное пособие рассчитано на младший школьный возраст, но при сложных речевых расстройствах, в том числе при задержке психического развития или легкой умственной отсталости, может использоваться в более старших возрастных категориях.
Обратите внимание на то, что из предлагаемых карточек вы можете выбирать те задания, которые необходимы в работе с конкретным ребенком. Построение материала от простого к сложному позволяет легко сориентироваться и, при желании, не только исключить часть упражнений, но и дополнить карточки новыми заданиями.
Карточки выполнены в программе Microsoft PowerPoint по нескольким причинам: программа позволяет выводить задания на экран в виде презентации, очень удобно добавлять слайды и упражнения, в том числе в анимированном виде, также карточки легко печатаются в разных форматах (А4, А5 и т.д.)
Построение материала от простого к сложному позволяет легко сориентироваться и, при желании, не только исключить часть упражнений, но и дополнить карточки новыми заданиями.
Карточки выполнены в программе Microsoft PowerPoint по нескольким причинам: программа позволяет выводить задания на экран в виде презентации, очень удобно добавлять слайды и упражнения, в том числе в анимированном виде, также карточки легко печатаются в разных форматах (А4, А5 и т.д.)
Содержание серии
«Звонкие и глухие парные согласные Б-П»
Карточка №1. Дифференциация звуков П-Б изолированно и в открытых слогах.
Карточка №2. Дифференциация звуков П-Б в закрытых слогах и словах.
Карточка №3. Дифференциация звуков П-Б в открытых слогах со стечением согласных и словах.
Карточка №4. Дифференциация звуков П-Б в словах и предложениях.
Карточка №5. Дифференциация звуков П-Б в словах и предложениях.
Карточка №6. Дифференциация звуков П-Б в предложениях и текстах.
Карточка №7. Дифференциация звуков П-Б в текстах.
Дифференциация звуков П-Б в текстах.
Карточка №1. Дифференциация звуков П-Б изолированно и в открытых слогах. 2. Вставь в слоги вместо наушников глухую согласную П, а вместо колокольчика – звонкую согласную Б. Прочитай (запиши) получившиеся слоги. А, О, У, Ы, Э, Я, Ё, Ю, И, Е 1. Продолжи ряды букв до конца строчки, следуя образцам. Во время записи озвучивай каждую букву, которую ты пишешь. П Б Б П … Б П Б П … Б Б П Б П… 4) П П Б Б П П …
Карточка №2. Дифференциация звуков П-Б
в закрытых слогах и словах.
__ык, пёс, __аран, __етух, со__ака, __оросёнок, жере__ёнок, ц ыплята.
1. Расшифруй слоги, где наушники – это глухой П, а колокольчик – звонкий Б. Прочитай (запиши) получившиеся слоги.
АЛ, ОЛ, УЛ, ЫТ, ЯТ, ЁТ, ЮШ, ИШ, ЕШ
2. Вставь в слова пропущенные буквы П и Б. Какой темой их можно объединить? Сделай анализ слов цветными карандашами по образцу (не забывай выделять согласные-исключения в кружок).
Вставь в слова пропущенные буквы П и Б. Какой темой их можно объединить? Сделай анализ слов цветными карандашами по образцу (не забывай выделять согласные-исключения в кружок).
Карточка №3. Дифференциация звуков П-Б в открытых слогах со стечением согласных и словах. Белка, __ельчонок, __ельчата, ка__ан, ка__аниха, ка__анята, вер__люд, вер__люжонок, антило__а, __арсук, __антера, __урундук, шим__анзе, чере__ахи, __егемот, __о__ры, __ума, лео__ард. 1. Расшифруй слоги, где наушники – это глухой П, а колокольчик – звонкий Б. Прочитай (запиши) получившиеся слоги. ТА, ЛО, КУ, ЛЫ, ТЯ, РЁ, ЛЮ, КИ, НЕ 2. Вставь в слова пропущенные буквы П и Б. Какой темой их можно объединить? Сделай анализ слов цветными карандашами по образцу (не забывай выделять согласные-исключения в кружок).
Карточка №4. Дифференциация звуков П-Б в словах и предложениях.
Лю__а ку__ила __атон __елого хле__а. Моя __а__ушка ис__екла __ирог с я__лочным __овидлом. __етя лю__ит есть тё__лые __улочки. __а__а от__равился на ры__алку.
1. Прочитай слоги. Составь из них слова и запиши. Какой темой их можно объединить? Сделай анализ слов цветными карандашами (не забывай выделять согласные-исключения в кружок). Выдели ударение в словах.
2. Прочитай предложения, вставляя пропущенные согласные П и Б. Обрати внимание на смысл предложений и определи одно лишнее. Объясни свой выбор.
Ка-печ, та-пли, тер-прин, пы-сос-ле, руб-мя-со-ка, пью-ком-тер, о-бо-ва-тель-гре, но-бук-ут.
Моя __а__ушка ис__екла __ирог с я__лочным __овидлом. __етя лю__ит есть тё__лые __улочки. __а__а от__равился на ры__алку.
1. Прочитай слоги. Составь из них слова и запиши. Какой темой их можно объединить? Сделай анализ слов цветными карандашами (не забывай выделять согласные-исключения в кружок). Выдели ударение в словах.
2. Прочитай предложения, вставляя пропущенные согласные П и Б. Обрати внимание на смысл предложений и определи одно лишнее. Объясни свой выбор.
Ка-печ, та-пли, тер-прин, пы-сос-ле, руб-мя-со-ка, пью-ком-тер, о-бо-ва-тель-гре, но-бук-ут.
Карточка №5. Дифференциация звуков П-Б в словах и предложениях.
__елая __а__очка летает над __оляной. __оря увидел __ожью коровку. На __олоте о__итают стрекозы. Ре__ята набрали __олную корзину гри__ов.
1. Составь из букв слова, которые подходят к теме «Морские обитатели». Запиши их. Сделай слоговой анализ слов и выдели в них ударение по образцу.
2. Прочитай предложения, вставляя пропущенные согласные П и Б. Обрати внимание на смысл предложений и определи одно лишнее. Объясни свой выбор.
Кбар, рбаы, чеерапах, ховтс, планвки, пнцаирь, щу паль ца.
Прочитай предложения, вставляя пропущенные согласные П и Б. Обрати внимание на смысл предложений и определи одно лишнее. Объясни свой выбор.
Кбар, рбаы, чеерапах, ховтс, планвки, пнцаирь, щу паль ца.
Карточка №6. Дифференциация звуков П-Б в предложениях и текстах. В су__ __оту мы всей семьей от__равились на рынок. Там нам __родали свежие я__локи, __ананы, а__ельсины и __ерсики. __осле __охода за фруктами мы __ристу__или к __риготовлению __олезных заготовок и __люд. 1. Прочитай слова, вставляя пропущенные буквы П и Б. Собери из слов предложения и запиши их. Выдели ударение и слоги в словах. 2. Прочитай текст, вставляя пропущенные согласные П и Б. Расскажи о чём рассказ и придумай его название. Перескажи текст. __осадила, __а__ушка, ка__усту, __олина. __арнике, в, __омидоры, с__еют, __ольшие.
Рабочие листы по фонетике: Полный список
Короткий гласный звук С помощью этих файлов ваши ученики будут практиковаться в чтении и написании слов с короткими и гласными звуками. Печатные формы включают в себя сортировку слов и изображений, карточную игру по звуку, упражнения по вырезанию и склеиванию, слайдеры для чтения и многое другое.
Печатные формы включают в себя сортировку слов и изображений, карточную игру по звуку, упражнения по вырезанию и склеиванию, слайдеры для чтения и многое другое.
Все задания, которые можно распечатать в этом модуле, содержат слова, которые имеют долгий звук и гласный звук. Есть колеса слов, карточные игры, упражнения по вырезанию и вставке, листы раскраски и многое другое.
Short A и Long A (Mixed)Рабочие листы на этой странице содержат слова с короткими и длинными гласными звуками. Эти печатные игры и рабочие листы требуют от учащихся сортировать или различать два звука.
Короткий гласный звук EПомогите студентам писать и читать слова с помощью короткого звука e гласного звука. На этой странице есть рабочие листы, счетчики для чтения, проекты вставки и вырезания и головоломки.
Long E Vowel Sound На нашей странице long e есть различные задания учебного центра, вырезания и склейки, а также сортировки слов.
На этой странице собраны рабочие листы и игры для печати со словами с гласными звуками короткой E и длинной E.
Short I Vowel SoundСосредоточьтесь на коротком I гласном с помощью этих распечатываемых листов по акустике.
Долгий I гласный звукЭти распечатываемые фонетические листы содержат слова с долгим I гласным звуком. Есть упражнения по вырезанию и склеиванию, колесики слов, слайдеры слов и многое другое.
Краткое I и Долгое I (смешанное)Рабочие листы на этой странице содержат слова как с долгим I, так и с коротким I гласными.Эти печатные формы требуют, чтобы ваши ученики рассортировали между двумя звуками.
Короткий гласный звук OЭтот набор заданий по акустике знакомит студентов с коротким звуком O.
Долгий гласный звук OВ этом сборнике распечатываемых листов по фонетике выделяются слова, в которых есть долгий гласный звук.
Short O & Long O (Mixed) С помощью этого набора заданий по фонетике вы сможете отличить слова с гласным звуком долгого O от гласного звука с коротким O.
Краткий U-гласный звук находится в центре внимания этих печатных мини-книг, игр и рабочих листов.
Долгий звук U, гласный звукЭти рабочие листы для печати предназначены для того, чтобы учащиеся читали и выучивали слова, которые имеют звук долгой буквы U.
Short U и Long U (смешанный)Учащиеся могут изучить различия между гласными долгими U и короткими U в словах.
Consonant B bРабочие листы, мини-книги и игры, в которых основное внимание уделяется согласной букве b.
Согласный C cПечатные игры, рабочие листы и мини-книги, в которых основное внимание уделяется согласной букве c.
Согласная D dРаспечатайте эти рабочие листы, в которых основное внимание уделяется согласной букве d.
Consonant F fРабочие листы, чтобы помочь студентам выучить букву f.
Consonant G gС помощью этих заданий учащиеся выучат звуки, издаваемые буквой g.
Consonant H h Рабочие листы, мини-книги и игры для печати с акцентом на букву h.
Полный комплект рабочих листов для согласной буквы j.
Consonant K kМатериалы для обучения студентов звуку буквы k.
Согласный L lУзнайте о согласной букве l с помощью этих распечатываемых листов.
Consonant M mРабочие листы, мини-книги для печати и карточные игры для согласной буквы m.
Согласный N nРаспечатайте рабочие листы, игры, мини-книги и задания на букву n.
Consonant P p.Практикуйте звук, издаваемый буквой p, с помощью этих распечатанных классных заданий.
Согласный Q qОвладейте звуком, издаваемым буквами qu, с помощью этих рабочих листов.
Consonant R rРабочие листы для печати, мини-книги и игры на букву r.
Согласная S sСогласная буква s находится в центре внимания этого набора рабочих листов по фонетике.
Consonant T tМини-книги, рабочие листы и многое другое на этой странице с буквой t.
Consonant V vРабочие листы для обучения студентов букве v.
Consonant W w Сортировка слов, операции вырезания и склейки, а также печатные формы для обучения звуку / w /.
Вот несколько упражнений для изучения звука / x /.
Согласный Y yДа, вы можете научиться читать о йо-йо, яках, желтках и пряжи с помощью рабочих листов / y /.
Consonant Z zИспользуйте эти рабочие листы и игры, чтобы попрактиковаться в чтении слов со звуком / z /.
Digraph: CHПрактикуйте звук / ch / с этими рабочими листами и упражнениями.
Digraph: SHНаучитесь произносить и читать звук / sh / с помощью этих распечатываемых листов и заданий.
Digraph: THИзучите два разных способа читать и произносить / th / с помощью этой коллекции печатных форм.
Digraph: WHПрактикуйтесь в чтении слов со звуком / wh /.
диграфов: Ch- и Sh- (смешанные)Эти рабочие листы помогут вашим ученикам научиться различать звуки / ch / и / sh / и их написание.
Семейство Blend: L-Family Blends Это звуковое устройство имеет множество рабочих листов для печати, содержащих слова из L-семейства, такие как: bl-, cl-, fl-, gl-, pl- и sl-.
Рабочие листы для печати для обучения студентов чтению и написанию основных слов, которые начинаются с букв br, cr, dr, fr, gr, pr и tr.
Смесь: BLЧитает и записывает слова со звуком / bl /.
Смесь: BRИспользуйте эти распечатанные задания, чтобы помочь студентам научиться сочетать согласные звуки BR.
Смесь: CLИспользуйте задания для печати на этой странице, чтобы помочь студентам практиковать смешение согласных CL.
Смесь: CRЭти печатные задания можно использовать, чтобы помочь студентам научиться сочетать согласные CR.
Смесь: DRШирокий выбор рабочих листов и заданий для студентов, чтобы узнать о смеси согласных DR.
Blend: FLЭтот блок содержит слова, начинающиеся со звука / fl /. Слова включают: фламинго, карточки, Флорида, зубная нить, флейта, муха, флаг, пламя и цветок.
Смесь: FRИспользуйте эти рабочие листы, чтобы научить студентов читать слова со звуком / fr /.
Смесь: GL Распечатайте рабочие листы по акустике и упражнения на этой странице, чтобы ваши ученики могли узнать о словах со смесью согласных GL.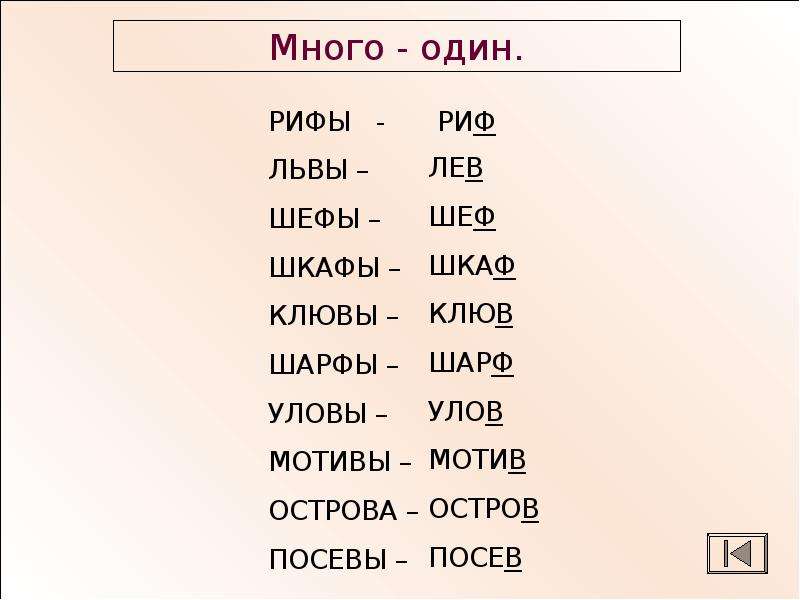
Используйте эти распечатываемые рабочие листы и задания по акустике, чтобы помочь студентам выучить слова со звуком / pr /. Включает слова: виноград, трава, зелень, и гриль .
Смесь: PLУчащиеся будут использовать этот широкий спектр рабочих листов и заданий, чтобы выучить слова со звуком / pl /.
Смесь: PRЭтот блок посвящен словам со смесью согласных PR. Вы найдете множество различных рабочих листов и заданий для студентов, чтобы попрактиковаться в чтении и письме, а также в определении их PR-слов.
Смесь: SCС помощью этой звуковой единицы научите своих студентов понимать слова со смесью согласных SC. Слова в этом модуле включают: разведчик, испуг, размах, беглец, чучело, шарф и совок.
Смесь: SKПри обучении своих учеников сочетанию согласных звуков SK вы найдете всевозможные печатные формы, такие как: колесо слов, упражнения по вырезанию и склеиванию, письменные задания, карточки и многое другое!
Blend: SL Используйте предложения, задания и мини-книги, чтобы передать звук SL.
Попробуйте читать и писать слова со звуком / sn /.
Blend: SPОзнакомьтесь с широким выбором печатных игр, заданий и рабочих листов со словами со смесью согласных SP (например: вращение, шпион, заклинание, весна и пробел.
Blend: STНаучите учащихся читать слова с помощью the / st / sound.
Blend: SWЭтот блок, выделяющий слова SW, имеет все виды рабочих листов для печати, включая головоломку для поиска слов, бегунок слов, колесо слов, карточки, операции вырезания и склеивания и многое другое!
Blend: TRРасскажите ученикам о смеси согласных TR с помощью этих заданий для печати, головоломок и рабочих листов.
Смесь: STRПрактикуйтесь в чтении и написании слов со звуком / str /.
r-контролируемых гласных: ARРабочие листы для печати с характерными словами с r-контролируемым гласным звуком, образованным буквами -ar. Иногда учителя неофициально называют гласные звуки с контролем r как звуки «Bossy R».
OI и OY Узнайте о звуке / ой / гласный с помощью этих печатных форм. Включает в себя дидактические карточки, слайдеры слов, штампы и действия для завершения предложений.
Включает в себя дидактические карточки, слайдеры слов, штампы и действия для завершения предложений.
Узнайте, что / ow / пишется с помощью ou и ow.
EE и EAУзнайте о длинном звуке e, записанном с помощью орграфов ee и ea.
OO WordsУзнайте о коротких и длинных звуках oo с помощью этих листов по акустике.
слов CVCРабочие листы на этой странице содержат слова с шаблоном согласный-гласный-согласный (CVC).
CVVC WordsРаспечатайте задания для обучения словам с образцом согласный-гласный-гласный-согласный.
CVCe (Silent e) WordsНа этой странице есть несколько различных типов заданий для изучения Silent E (CVCe) слов.
Начальные, средние и
конечные звуки
Эти рабочие листы и игры можно использовать, чтобы помочь учащимся распознавать начальные согласные звуки в словах.
Конечные согласные На этих рабочих листах учащиеся определяют, какие согласные звуки находятся в конце каждого слова.
У нас есть единицы семейства слов для десятков семейств слов, в том числе -ack , -ad , -ag , -ail , -ake , -all , -ap , -an , -am , -and , -at , -ate , -aw , -ay , -eal , -ear , -eep , -eel , -eet , -ent , -ell , -ight , -ime , -ine , -ing , -ook , -op , – поток , – выход и – насос .
Колеса слов (семейства слов)Практикуйтесь в чтении наборов семейств слов с этими колесами слов.
Единицы контрольного словаУ нас есть 30 недель контрольных единиц слова. Каждый блок выделяет пять слов, которые дети должны выучить, и включает в себя различные игры со словами с прицелом, рабочие листы и занятия в учебном центре.
контрольных слов (отдельные) Загрузите распечатанные рабочие листы для более чем 200 отдельных контрольных слов. Каждое слово содержит около девяти листов.
Каждое слово содержит около девяти листов.
Sight word bingo, колеса слов и карточки.
Fry Instant Sight WordsИспользуйте эти инструменты, чтобы помочь своим ученикам освоить списки Fry Instant Word.
Alphabet CrownsРаспечатайте шляпы с буквами и цифрами, которые ваши ученики могут раскрасить и носить в школе. На каждой шляпе изображена буква (или цифра) дня с картинками.
Мини-книги по акустикеРаспечатайте эти крошечные 8-страничные мини-книги для каждого согласного и гласного звука.
Словарные лестницыЧтобы решить эти фонетические головоломки, ученики меняют буквы в данных словах, чтобы составить новые слова.(Уровень: очень базовый)
Акустика для старшеклассников
Акустика для старших учеников (общий)Акустика гласные звуки, смеси и дифтонги для старшеклассников.
Акустика для старших школьников: долгие и короткие гласныеРаспознавайте долгие и короткие гласные в словах.
Рабочие листы по чтению и письму – Полный список Рабочие листы для печати, чтобы помочь студентам выучить длинные и короткие гласные звуки.
Математика для ИИ: все необходимые вам математические темы | Абхишек Парбхакар
Взаимосвязь между ИИ и математикой можно описать следующим образом:
Человек, работающий в области ИИ, не знающий математики, подобен политикам, не умеющим убеждать.У обоих есть неизбежная область для работы!
Я не буду больше тратить время на важность изучения математики для ИИ и сразу перейду к основной цели этой статьи.
Популярная рекомендация по изучению математики для ИИ звучит примерно так:
- Изучите линейную алгебру, вероятность, многомерное исчисление, оптимизацию и несколько других тем
- А еще есть список курсов и лекций, которым можно следовать, чтобы выполнить тот же
Хотя вышеупомянутый подход совершенно хорош, я лично считаю, что есть другой подход, который лучше, особенно для людей: 1) у которых нет солидного количественного фона и 2) нет времени на выполнение всех предварительных требований. математические курсы.То есть:
Вместо того, чтобы идти по темам, переходите по темам.
Например, при изучении многомерного исчисления вы встретите знаменитую теорему Стокса, но окажется, что велика вероятность того, что она не принесет вам немедленной пользы на практике и даже при чтении научных статей. . Таким образом, изучение предметов (курсов) может занять много времени, и вы можете потеряться в бескрайнем море математики.
Я рекомендую вам:
- перейти по темам , сначала изучить основные концепции, объединить их
- И только потом переходить к другим концепциям, с которыми вы сталкиваетесь во время практической реализации и чтения литературы
Вот список основных тем по каждому предмету:
Линейная алгебра
- Векторы
определение, скаляры, сложение, скалярное умножение, внутреннее произведение (скалярное произведение), векторная проекция, косинусное подобие, ортогональные векторы, нормальные и ортонормированные векторы, векторная норма , векторное пространство, линейная комбинация, линейная оболочка, линейная независимость, базисные векторы - Определение матриц
, сложение, транспонирование, скалярное умножение, умножение матриц, свойства умножения матриц, произведение Хадамара, функции, линейное преобразование, определитель, единичная матрица, обратимая матрица и обратные, ранговые, следовые, популярные типы матриц – симметричные, диагональные, ортогональные или тонормальная, положительно определенная матрица - Собственные значения и собственные векторы
концепция, интуиция, значимость, как найти - Анализ основных компонентов
концепция, свойства, приложения - Разложение по сингулярным значениям
концепция, свойства, приложения
Исчисление
- Функции
- Скалярная производная
определение, интуиция, общие правила дифференцирования, цепное правило, частные производные - Градиент
концепция, интуиция, свойства, производная по направлению - Векторное и матричное исчисление
как найти производную от {скалярно-значного, векторного- оцененная} функция относительно {скаляр, вектор} -> четыре комбинации – Якобиан - Градиентные алгоритмы
локальные / глобальные максимумы и минимумы, седловая точка, выпуклые функции, алгоритмы градиентного спуска – пакетный, мини-пакетный, стохастический, сравнение их производительности
Вероятность
- Основные правила и xioms
события, пространство выборки, частотный подход, зависимые и независимые события, условная вероятность - Случайные переменные – непрерывные и дискретные, математическое ожидание, дисперсия, распределения – совместные и условные
- Теорема Байеса, MAP, MLE
- Популярные распределения – биномиальные , Бернулли, Пуассон, экспонента, гауссовский
- Сопряженные априорные значения
Разное
- Теория информации – энтропия, кросс-энтропия, расхождение KL, взаимная информация
- Цепь Маркова – определение, матрица переходов, стационарность
Любой источник, который вам подходит, будь то видео на YouTube или классический учебник.
Если вы не уверены, выполните простой поиск в Google по каждой теме [<название темы> + «машинное обучение»] и прочтите основные ссылки, чтобы получить более широкое представление.
Список может показаться длинным, но он может сэкономить вам много времени. Чтение приведенных выше тем придаст вам уверенности, чтобы погрузиться в глубокий мир ИИ и исследовать больше самостоятельно.
Полное руководство по искусственному интеллекту в радиологии
Перво-наперво: некоторые основные концепции искусственного интеллекта
Прежде чем мы начнем, давайте удостоверимся, что мы полностью понимаем друг друга, определив некоторые концепции, используемые на этой веб-странице.
Что такое алгоритм?
Алгоритм – это набор пошаговых инструкций, которым можно следовать для достижения цели или решения проблемы. Рецепт приготовления может быть алгоритмом, как и направление в больницу. Однако в большинстве случаев мы ссылаемся на компьютерных алгоритма . Это фрагменты компьютерного кода, предназначенные для решения конкретных задач. Вы вставляете данные, компьютерный алгоритм выполняет вычисления на основе этих данных и дает вам результат; решение проблемы.В контексте радиологии алгоритм обычно представляет собой фрагмент компьютерного кода, который принимает медицинское изображение в качестве входных данных и возвращает ответ, чтобы помочь рентгенологу в его / ее анализе.
Что такое (обучающие) данные?
Для построения алгоритма вам (почти) всегда нужен набор данных, обучающие данные , чтобы начать работу. Этот набор данных будет пакетом данных того типа, который вы хотите, чтобы ваш алгоритм анализировал. В радиологии это будут данные изображения. В зависимости от типа используемого алгоритма вам также может потребоваться дополнительная информация.Это может быть информация о том, что вы видите на изображении (например, сегментация) или другая информация о пациенте.
Что такое этикетка?
Для большинства алгоритмов необходим набор данных с меткой . Это означает, что для каждой точки данных в вашем наборе данных (в радиологии, для каждого изображения) вы знаете основную истину: метку. Например, если вы хотите создать алгоритм, который может различать злокачественные и доброкачественные опухоли, медицинские изображения в вашем наборе данных должны содержать опухоли, и каждое изображение должно иметь метку «доброкачественная» или «злокачественная».Это поможет компьютеру узнать, как можно распознать различные типы опухолей на изображениях.
Что такое функция изображения?
Характеристика изображения – это измеримая характеристика или особое свойство, которое вы можете найти в каждом изображении обучающих данных. Например, если ваши входные данные представляют собой набор рентгеновских изображений бедра, функции изображения могут включать форму головки бедренной кости пациента, но они также могут быть более абстрактными, такими как распределение значений шкалы серого внутри бедренной кости. голова.
Что такое пространство функций?
Все объединенные функции могут быть представлены в пространстве функций . Визуальное представление пространства функций (отображение функций на графике) может помочь получить обзор всех значений функций. Самый простой пример – когда в вашем наборе данных есть две функции. Вы визуализируете это, рисуя график с одним элементом на оси x и другим элементом на оси y. Каждое изображение может быть представлено на этом графике путем рисования точки в местоположении (X, Y), где X – значение изображения для первой функции, а Y – значение изображения для второй функции.Анализ данных в (правом) пространстве функций упрощает обнаружение корреляций, которые не очевидны при просмотре исходных данных.
AI с самого начала
Ожидается, что искусственный интеллект сыграет огромную роль в преобразовании радиологической практики. Поэтому мы стремимся дать подробное объяснение самых основ искусственного интеллекта. Что это такое и как работает?
Модные словечки в перспективе
Всякий раз, когда обсуждают искусственный интеллект, используются такие слова, как машинное обучение, глубокое обучение и большие данные… но кто знает его машинное обучение из его глубокого обучения? Давайте получше представим некоторые из этих модных словечек. Как связаны друг с другом ИИ, машинное обучение и глубокое обучение? Схематический обзор месторождения в целом показан на Рисунке 1 ниже. Искусственный интеллект – это область науки, при этом машинное обучение является важной под-областью, а глубокое обучение – под-областью машинного обучения. Отличительные характеристики каждого поля обсуждаются в разделах ниже. 2
Рис. 1. Схематический обзор ИИ, машинного обучения и глубокого обучения. 2
Что такое искусственный интеллект и как он работает?
В зависимости от контекста можно использовать несколько определений искусственного интеллекта. Многие из этих определений связывают человеческое поведение с (предполагаемым) поведением компьютера. В случае радиологии эти определения не совсем охватывают сферу ИИ, поскольку во многих ситуациях ИИ превосходит человеческие возможности. В радиогеномике, например, мы связываем генетическую информацию с тем, что мы видим на медицинских изображениях, что позволяет нам прогнозировать наличие или отсутствие генетических мутаций в опухоли, что может использоваться для определения дальнейшей диагностики и лечения.Другой пример – применение глубокого обучения (DL) для реконструкции изображений в МРТ или КТ, которое называется глубокой визуализацией. Качество изображения можно повысить с помощью алгоритмов DL, которые преобразуют необработанные данные в k-пространстве МРТ-сканирования в изображение. Определение ИИ, которое соответствует этим критериям, может быть
.«раздел информатики, касающийся моделирования разумного поведения человека в компьютерах».
Уточнение этого определения ИИ даже в контексте радиологии приводит к
«раздел информатики, связанный с получением, реконструкцией, анализом и / или интерпретацией медицинских изображений путем моделирования интеллектуального поведения человека на компьютерах»
В области искусственного интеллекта существует множество методов.Как обсуждалось ранее, машинное обучение охватывает часть этой области, а глубокое обучение является одним из методов машинного обучения (честно говоря, существует множество способов реализации глубокого обучения, но мы вернемся к этому позже). В этом разделе мы обсудим несколько методов, которые относятся к сфере AI, но не относятся к ML или DL.
Пример ИИ: движки на основе правил
Механизмы на основе правил являются одними из самых простых алгоритмов . Визуально они могут быть представлены деревом решений.Такой алгоритм представляет собой реализацию вопросов, задаваемых компьютером в определенном порядке, чтобы прийти к окончательному ответу. Мало чем отличается от деревьев протоколов принятия решений, используемых в больницах для управления процессами. Идея и реализация могут быть довольно простыми. Однако чем более детализирована ваша проблема, тем больше вопросов вам нужно задать, а значит, тем сложнее становится ваш алгоритм. Кроме того, вы должны принять во внимание, что на каждый вопрос нужен «подалгоритм», способный найти ответ.Например, если вы хотите узнать, есть ли у опухоли острые края, вам понадобится «вспомогательный алгоритм», который сможет определить, какие края видны на изображении.
Рис. 2. Механизм на основе правил является примером метода ИИ. Фактически это можно сравнить с компьютерной версией дерева решений: компьютер выполняет запрограммированную схему вопросов, помогая ему решить основную проблему. На изображении выше вопрос, является ли опухоль олигодендроглиомой или астроцитомой?
Что такое машинное обучение (ML) и как оно работает?
Алгоритмы машинного обучения – это подмножество методов искусственного интеллекта, отличающееся тем, что вам не нужно заранее указывать компьютеру, как решить проблему.Вместо этого компьютер учится решать задачи, распознавая закономерности в данных.
В чем разница между обучением с учителем и обучением без учителя?
Методы машинного обучения можно разделить на контролируемые и неконтролируемые алгоритмы. Эта категоризация связана с типом данных, используемых для разработки алгоритма.
Контролируемые методы используют набор данных, который помечен, что означает, что достоверная информация доступна в базе данных. В случае медицинской визуализации это может быть, например, сегментация ткани головного мозга (полученная вручную), ответ да / нет на вопрос, есть ли у пациента перелом, или шкала Келлгрена-Лоуренса для оценки остеоартрита на рентгеновских снимках. бедра. 3
Неконтролируемые методы, с другой стороны, используют набор данных без меток. Эти алгоритмы обычно разрабатываются путем предоставления ему большого стека данных, в котором алгоритм сам по себе найдет корреляции между функциями, присутствующими на изображениях, то есть он начнет распознавать шаблоны. На основе этих шаблонов алгоритм разделит набор данных на отдельные группы, например, сканирование мозга с метастазами и без них. 4 Преимущество обучения без учителя состоит в том, что эти методы позволяют находить шаблоны, скрытые от человеческого глаза.Например, неконтролируемый обученный алгоритм может распознавать опухоли на МРТ головного мозга, которые еще не различимы для радиологов. 5
Третий вариант между контролируемыми и неконтролируемыми методами – это полу-контролируемые методы. Этот подход использует меньший набор помеченных данных в сочетании с большим набором немаркированных данных. Помеченный набор данных используется для создания алгоритма и направляет его в правильном направлении, после чего он уточняет себя, используя немаркированные данные.Этот метод может быть эффективным, когда ясно, какой тип результата вы хотите, но трудно получить набор данных с метками хорошего качества. Например, сканирование мозга с вручную сегментированной гиперинтенсивностью белого вещества очень трудоемко для создания и должно соответствовать очень высокому стандарту качества, поэтому создание большого помеченного набора данных для выполнения полностью контролируемого обучения может быть длительным и, следовательно, дорогостоящим процессом. 6 Вместо этого можно использовать полууправляемую стратегию с подмножеством помеченных вручную изображений (например,г. с сегментацией гиперинтенсивности белого вещества), которую можно комбинировать с большим набором данных без метки.
Рис. 3. Все методы машинного обучения можно разделить на три группы: контролируемое обучение, частично контролируемое обучение и неконтролируемое обучение, при этом данные полностью помечены, частично помечены или полностью немаркированы.
Другой способ категоризации пространства машинного обучения – посмотреть, какие цели преследуют алгоритмы. Распределяет ли алгоритм изображения или пациентов по определенным категориям? Прогнозирует ли он постоянное значение? Или группирует данные без доступа к ярлыкам? Различные типы алгоритмов, отвечающие этим описаниям, обсуждаются в следующих разделах.
Что такое методы классификации?
Алгоритмы классификации классифицируют входные данные, которые они получают. Например, является ли опухоль головного мозга олигодендроглиомой или астроцитомой, а также достоверность этой классификации. Схематическое представление приведено на рисунке 4. Алгоритмы классификации обычно создаются с использованием помеченных изображений. Поскольку вы точно знаете, в какие классы вы хотите классифицировать свой ввод, это контролируемый метод.
Рисунок 4: Схематическое представление алгоритма классификации.Алгоритм классифицирует входные изображения по разным категориям. В этом примере категория олигодендроглиомы или категория астроцитомы.
Пример методики классификации: машина опорных векторов
Примером базового алгоритма классификации является машина опорных векторов, или сокращенно SVM. Идея SVM проста. Сначала вы выбираете определенные функции (изображения), на которых вы хотите обучить алгоритм. К таким особенностям относятся, например, распределение оттенков серого на изображении или наличие определенных форм.Самое главное, эти особенности должны быть известны для всех изображений, которые вы используете для разработки алгоритма. Во-вторых, эти обучающие данные отображаются в пространстве признаков (рис. 5, левая панель). Поскольку SVM – это алгоритм классификации, он будет пытаться отсортировать данные по нескольким классам. В нашем примере два класса обозначены зелеными и синими кружками. Чтобы отсортировать данные, необходимо знать, к какому классу принадлежит каждая точка данных, т. Е. Набор данных должен быть полностью помечен. Для простоты на этом рисунке показано двухмерное пространство признаков, со значением одного объекта на оси x и значением другого объекта на оси y.Однако эти пространственные объекты могут содержать гораздо больше измерений.
Рисунок 5: Левая вставка показывает пример «пространства признаков» с двумя объектами данных, что приводит к двум осям. В этом пространстве будут нанесены все точки данных в соответствии с их значением для функции 1 и функции 2. На средней вставке показано, как SVM определяет линию, которая наилучшим образом разделяет два класса данных. Метод называется SVM из-за векторов, стрелок (обозначенных оранжевым), которые используются для вычисления линии.На правой вставке показано, что в зависимости от того, как каждая новая точка данных отображается в пространстве признаков, определяется, к какому классу она принадлежит (то есть с какой стороны границы она находится).
В-третьих, алгоритм случайным образом выбирает линию, разделяющую два класса в этом пространстве. Расположение этой границы оптимизируется, выбирая ее как можно дальше от точек данных класса A, а также от точек данных класса B. Другими словами, алгоритм стремится максимизировать расстояние между данными. точки и линия.Это делается путем выбора двух точек (по одной каждого класса), ближайших к этой случайной линии. SVM будет рисовать «опорные векторы» между точками данных и линией, как показано на средней панели на рисунке 5. Последний шаг – перемещать линию, пока не будет найдено оптимальное местоположение. Это когда длина объединенных опорных векторов является наибольшей. После того, как определено, где должна быть эта граница, алгоритм практически готов. Чтобы классифицировать новое изображение, оно наносится в пространство признаков, чтобы определить, на какой стороне границы оно заканчивается.И вот он: алгоритм, способный классифицировать новые точки данных. 7
Другой пример классификации: K-Nearest-Neighbours
Другой пример метода классификации – метод K-ближайших соседей (KNN). Как и в случае с SVM, данные обучения отображаются в пространстве признаков (рисунок 6). Однако назначение классов происходит на основе определенного количества (K) ближайших точек данных. Например, на крайнем левом изображении на рисунке 6 для K равно 1, вы проверяете, какая отдельная точка данных находится ближе всего к вашему тестному примеру (оранжевая точка), рисуя круг (оранжевый круг), который достаточно велик, так что один дополнительный точка данных попадает в этот круг.В этом примере мы назначим эти точки классу A. На средней панели K равно 3, что означает, что размер круга увеличился, так что в него включены 3 точки данных. Затем алгоритм подсчитывает, сколько из этих точек принадлежит классу A или классу B, и присваивает новую точку определенному классу в зависимости от того, к какому классу принадлежит большинство точек в круге. В средней и правой панелях это класс B, поэтому новая точка данных классифицируется как класс B. Для более внимательных читателей: разработчик алгоритма должен указать, используется ли простое большинство для классификации или какой-либо другой отрезать.
Рисунок 6. Метод K-ближайшего соседа использует K-ближайшие точки данных для классификации новой точки данных. Если большинство этих K точек данных относятся к определенному классу, новая точка данных будет классифицироваться как этот конкретный класс.
Что такое методы регрессии?
Другой набор широко используемых методов машинного обучения – это методы регрессии. Методы регрессии помогают прогнозировать непрерывное значение на основе входных данных, в отличие от дискретного значения, например.г. класс, как описано в разделе классификации выше. Например, входными данными может быть МРТ с использованием жирного контрастного изображения, а выходными данными – уровень оксигенации ткани. Поскольку алгоритм должен предсказать значение конкретной переменной, выбранной заранее, обучающие данные должны быть помечены этой переменной, следовательно, методы регрессии являются контролируемыми методами обучения.
Пример регрессии: машины опорных векторов
Звучит знакомо! Хорошо, вы обратили внимание.Наряду с проблемами классификации, машины опорных векторов (SVM) также являются подходящим методом для решения задач регрессии. Если вы пропустили объяснение метода SVM в задачах классификации, рекомендуется вернуться и сначала прочитать этот раздел.
Основное различие между SVM для решения задач классификации и SVM для решения задач регрессии – это конечная цель. Для проблем классификации вы начинаете с набора данных, который состоит из точек данных двух разных классов, и вы хотите определить для новой точки данных, больше ли она похожа на класс A или класс B.Для проблем регрессии вы начинаете с набора данных, который имеет только один класс, и ищете корреляцию между различными функциями этого набора данных. Примером может служить оценка содержания кальция в коронарных артериях на КТ. На входе – изображение, на выходе – непрерывное число. Это уже применяется во многих больницах: алгоритмы регрессии в действии! 8
Построение SVM регрессии работает следующим образом. Сначала выбираются определенные особенности изображения, с которыми обучается алгоритм. Важно отметить, что все эти функции должны быть известны для каждой точки данных.Во-вторых, эти обучающие данные отображаются в пространстве признаков. На рисунке 7 мы снова показываем пример двумерного пространства признаков, но также для SVM регрессии алгоритм может быть разработан с использованием пространства признаков гораздо большего числа измерений. Аналогично классификационным SVM, линия определяется путем минимизации расстояния точек данных до линии. Однако эта линия не используется для классификации точек данных в отдельные классы. Вместо этого линия описывает математическую связь между изменением одной функции и результирующим изменением другой функции.Другими словами, линия используется для прогнозирования значений (значений y) на основе ввода от нового субъекта (значений x). Здесь и вступают в игру «опорные векторы» (средняя панель на рисунке 7). В этом примере показаны два оранжевых опорных вектора (в действительности, каждая точка данных получит такой вектор). Длина всех этих векторов суммируется, и линия корректируется до тех пор, пока для нее не будет найдено правильное местоположение, то есть когда сумма длин всех векторов достигнет минимального значения. Конечным результатом является линия, которая выражает корреляцию между объектом 1 и объектом 2 для этого набора данных.Для новой точки данных, о которой вы знаете только функцию 1, теперь вы можете предсказать, какой будет функция 2. Важно понимать, что для пространств признаков более высокой размерности эта «линия» регрессии может принимать сложные нелинейные формы.
Рис. 7: Левая вставка показывает пример пространства признаков с двумя объектами данных, что приводит к двум осям. Все точки данных нанесены в этом пространстве в соответствии с их значением для функции 1 и функции 2. На средней панели показаны опорные векторы (обозначены оранжевым цветом), которые помогут определить линию, которая наилучшим образом представляет корреляцию между характеристикой 1 и 2 для этого набора данных. .На правой вставке показано, как линия регрессии используется для прогнозирования значения признака 2, когда известно только значение признака 1.
Что такое методы кластеризации?
Кластеризация очень похожа на классификацию в том смысле, что эти методы группируют входные данные в разные классы на основе предопределенных функций. Однако методы кластеризации обычно используются, когда для разных классов нет доступных меток. Таким образом, алгоритмы кластеризации определяют свою собственную систему группировки (или, если хотите, «маркировку») для классификации входных данных.Следовательно, это следует рассматривать как метод обучения без учителя. Давайте разберемся, как работают методы кластеризации, на примере.
Пример кластеризации: кластеризация K-средних
Кластеризация K-средних является основным примером метода кластеризации. Это итерационный метод, означающий, что процесс повторяется до тех пор, пока не будет найдено оптимальное распределение классов. Во-первых, все точки данных отображаются в пространстве признаков. Во-вторых, все точки данных случайным образом назначаются одному из кластеров K, и положение центроида или геометрического центра определяется для каждого кластера.Во второй итерации каждая точка данных переназначается новому кластеру на основе его ближайшего центроида. Новые местоположения центроидов устанавливаются на основе этих новых назначений кластеров. Этот процесс повторяется (или «повторяется») до тех пор, пока кластерное назначение точек данных не перестанет меняться. 8 В это время определяется оптимальное разделение точек данных на кластеры и, следовательно, устанавливается оптимальное расположение центроидов. См. Рисунок 8 для визуального объяснения. Затем каждая новая точка данных сравнивается с местоположением этих конечных центроидов и классифицируется.
Рисунок 8: Кластеризация K-средних делит набор данных на K меньших наборов данных на основе оптимальных центроидов для каждого класса.
А как насчет (искусственных) нейронных сетей?
Нейронные сети также являются частью области машинного обучения. Это особая группа методов, которые решают проблемы классификации, но они также подходят для работы в качестве метода регрессии или кластеризации или могут выполнять задачи сегментации. Нейронные сети могут использоваться как в контролируемых, так и в неконтролируемых алгоритмах; следовательно, это очень универсальный набор техник.В следующих разделах мы объясним, как простые нейронные сети творят свое волшебство, а в следующем разделе мы погрузимся в глубокие нейронные сети.
Как работают нейронные сети?
Простая нейронная сеть, также называемая персептроном , состоит из двух слоев, каждый из которых состоит из «узлов» (мы поговорим об этом подробнее в разделе «Что происходит в узлах нейронной сети?»). Нейронные сети содержат входной и выходной слой. Входной слой получает функции изображения, которые вручную извлекаются из изображения, и выполняет определенные вычисления с использованием этих функций.Выходной слой получает результаты вычислений от узлов входного слоя и дает вам результат на вопрос, на который должна ответить нейронная сеть. Когда мы перейдем к разделу о глубоком обучении, мы увидим, что в глубоких нейронных сетях входной слой на самом деле – это изображение. Однако с перцептроном дело обстоит иначе.
Пример показан на рисунке 9, где мы ищем ответ на вопрос «какой тип опухоли можно увидеть на входном изображении?» Прежде чем данные попадут в перцептрон, нам нужно спроектировать и получить характеристики изображения во время предварительной обработки.Затем входной слой получает эти функции изображения и выполняет вычисления на основе этих функций. Выходной слой сообщает вам, какой тип опухоли сеть ожидает показать на входном изображении.
Рис. 9. Простая нейронная сеть, перцептрон, состоит из двух слоев: входного и выходного. Передавая информацию, поступающую из входного изображения в выходной слой, алгоритм находит ответ, в данном случае, на вопрос «Какой тип опухоли показан на изображении?».
Обязательно ли нейронная сеть «глубокая»? Нет это не так. До сих пор мы обсуждали простые нейронные сети. В следующем разделе мы рассмотрим глубокие нейронные сети.
Что такое глубокое обучение (DL) и как оно работает?
Глубокое обучение – это подмножество машинного обучения, основным отличительным фактором которого является то, что в глубоком обучении используются «глубокие нейронные сети», тогда как машинное обучение включает гораздо более широкий набор методов. Глубокие нейронные сети похожи на простую сеть, описанную ранее.Однако глубокие сети имеют скрытых слоя между входным и выходным слоями для уточнения вычислений и, следовательно, прогнозов. Схематический обзор глубокой нейронной сети приведен на рисунке 10. Простые нейронные сети требуют предварительной обработки для получения характеристик изображения, которые будут входными данными для сети, тогда как глубокие нейронные сети могут использовать изображение непосредственно в качестве входных данных.
Рис. 10: Глубокие нейронные сети – это расширение «обычных» нейронных сетей.В отличие от простых или неглубоких нейронных сетей, они используют скрытые слои перед передачей результатов в выходной слой.
Что происходит в узлах нейронной сети?
В контексте радиологии входным слоем может быть медицинское изображение (или все пиксели медицинского изображения). В идеальном мире каждый пиксель был бы назначен отдельному узлу. Однако из-за ограничений памяти мы обычно работаем с наборами пикселей, которые назначаются отдельному узлу. Затем эти узлы передают значение наборов пикселей на первый скрытый слой.Один узел входного слоя подключается ко всем узлам скрытого слоя. Это просто означает, что значение из этого первого входного узла передается всем узлам в скрытом слое и используется там в вычислениях. Это называется – полносвязный слой .
В скрытых слоях происходит волшебство. Они получают входные данные от узлов в предыдущем слое (это может быть входной слой или другой скрытый слой) и выполняют вычисления, используя эти входные данные в сочетании с набором весов.Конечным результатом является вывод, который передается от этого узла скрытого слоя к следующему скрытому слою или к слою вывода. 9 Цель обучения нейронной сети – определить оптимальное значение весов каждого узла. Чем выше точность вашего алгоритма, тем точнее вы определили свои веса. См. Рисунок 11 для схематического обзора этого процесса.
Рисунок 11: Узел в скрытом слое получает входные данные от узлов входного слоя, выполняет вычисления с использованием определенных весов и затем передает новые значения на следующий (выходной) уровень.
Выходной слой получает свои входные данные от последнего скрытого слоя и объединяет эти входные данные в окончательный ответ. Выходной слой нашего примера глубокой нейронной сети на рисунке 10 состоит из двух узлов: первый вернет «положительный результат», если алгоритм классифицирует опухоль как олигодендроглиому, а второй вернет положительный результат, если алгоритм классифицирует опухоль как астроцитому. .
Как искусственный интеллект может помочь рентгенологу?
Радиологи – чрезвычайно занятые специалисты в области здравоохранения.Они не могут позволить себе совершать ошибки. Им необходимо взаимодействовать с широким кругом лечащих врачей; неврологи, урологи, практикующие ортопеды – этот список можно продолжить. Они всегда должны быть острыми. Что ИИ может дать этим напряженным рентгенологам и сделать их еще лучше?
Каковы преимущества искусственного интеллекта в радиологии?
Есть несколько способов, с помощью которых ИИ может еще больше улучшить работу радиологов. В этом разделе мы обсудим некоторые из этих подходов.Этот список не является исчерпывающим. У ИИ есть еще много способов помочь радиологу. В будущем мы расширим этот раздел.
Обеспечьте более дифференцированный диагноз
Многие решения AI ориентированы на предоставление дополнительной информации. Это может быть выполнено путем количественной оценки информации, заключенной в изображении, где в настоящее время она представлена только качественным образом. Или программное обеспечение может добавлять нормативные значения, позволяя врачам сравнивать результаты пациентов со средним значением на основе поперечного сечения населения.Сложность с этим преимуществом заключается в том, что мы еще не всегда знаем, как обрабатывать эту дополнительную информацию. Что означает конкретное значение? Когда пациент значительно отличается от популяции и что это означает для постановки диагноза? Поскольку у нас еще мало опыта с количественной информацией, часто нет руководящих принципов (пока!) О том, что эта информация означает или что радиолог должен с ней делать.
Возьмите на себя повторяющиеся рутинные задачи
AI не во всем хорош.По крайней мере, пока. Какие задачи лучше всего передать AI? Задачи, для которых у нас имеется множество доступных данных, которые довольно просты и не требуют объединения большого количества различных входных данных. Отсюда простые рутинные задачи, которые рентгенологи выполняют очень много. Обычно это касается более монотонных задач, то есть задач, которые рентгенологи считают обременительными.
Предложите второе мнение
Запуск алгоритма искусственного интеллекта в фоновом режиме предлагает простой способ получить второе мнение.Результаты алгоритма могут служить простой резервной проверкой диагноза врача. Дополнительным преимуществом использования программного обеспечения ИИ в качестве второго мнения является то, что он позволяет рентгенологу постепенно привыкать к работе с ИИ и укреплять доверие, поскольку они видят, что это повышает ценность. Чтобы хорошо служить этой цели, очень важно, чтобы программное обеспечение работало надежно и не возвращало много ложных срабатываний или отрицательных результатов. Кроме того, крайне важно иметь процедуры на тот случай, когда программное обеспечение ИИ ставит другой диагноз, чем это сделал врач.
Устранение изменчивости между наблюдателями и внутри наблюдателя
Даже самые подготовленные и опытные радиологи могут иногда отличаться в своем диагнозе. Хорошо отдохнувшим утром, вы можете привлечь внимание к чему-то другому, чем после долгого рабочего дня. Кроме того, разные радиологи могут подчеркивать разные аспекты в своих отчетах. Это может быть сложно для направляющих врачей, поскольку они должны учитывать эти различия при обобщении всей имеющейся информации, прежде чем прийти к окончательному диагнозу.Программное обеспечение AI имеет возможность уменьшить или даже устранить эту вариативность между отчетами радиолога.
Как радиология с искусственным интеллектом реализует эти преимущества?
Есть много задач, которые AI может выполнять в контексте радиологии. Некоторые задачи потребуют только медицинского изображения в качестве входных данных и будут основывать анализ исключительно на пикселях (или вокселях). Другие сделают еще один шаг и объединят радиологические изображения с информацией, полученной из других источников. О каком типе анализа вам следует подумать в обеих этих категориях?
Использование только изображения в качестве входных данных
AI, который использует только медицинское изображение в качестве входных данных, даст результаты, которые в основном аналогичны тем, которые рентгенологи в противном случае делали бы вручную.Например, автоматическое сегментирование определенных органов может выполняться вручную (например, сегментация печени и ГЦК, чтобы определить, можно ли и нужно ли выполнять резекцию). Однако этот тип анализа требует очень много времени и поэтому очень подходит для «аутсорсинга» алгоритма. Другой пример – количественная оценка конкретных расстояний (например, автоматическое измерение баллов по шкале RECIST). Опять же, это можно сделать вручную, но многие радиологи воспринимают это как монотонную задачу, что делает ее подходящим кандидатом для получения помощи от искусственного интеллекта.
Добавление другой информации из других обследований пациентов
Объединение медицинских изображений с другой информацией может привести к пониманию, которое не всегда легко получить рентгенологам. Подобные виды анализа обычно считаются более футуристическими. Например, связав данные изображения с результатами лаборатории патологии, можно позволить алгоритму извлекать информацию о патологии из медицинского изображения. Другой пример – алгоритм, который извлекает генетические данные из изображений без доступа к генетическим разметкам пациента.
Другой тип анализа – добавление нормативной информации. Например, сравнивая объемы органов пациента со средним населением. Это может быть полезно при исследовании деменции (сравнение объемов конкретных структур мозга с нормативной базой данных) или в случае увеличения селезенки.
Как искусственный интеллект может помочь рентгенологу помочь пациентам?
Каждый диагностический процесс направлен на достижение наилучших результатов для пациентов. Медицинская визуализация все чаще становится частью диагностической цепочки и поэтому должна быть нацелена на одну и ту же конечную цель: принести пользу пациенту.Следовательно, для каждого решения искусственного интеллекта, используемого радиологами для оценки изображений, мы должны провести лакмусовую бумажку и спросить: «В конце концов, приносит ли это программное обеспечение пользу пациенту?» Проще говоря, вы можете думать о пользе для пациентов по двум осям: по оси качества и по оси эффективности. Мы обсудим оба ниже.
Повышение качества для улучшения результатов лечения пациентов
AI предлагает большой потенциал для повышения качества текущих показаний изображений. Например, выполняя анализ, который в настоящее время не выполняется, поскольку радиологу требуется слишком много времени для выполнения его вручную.Примером могут служить объемные измерения органов, когда ручное определение границ требует слишком много времени, но может повысить точность диагноза. Кроме того, ИИ – важный инструмент точной медицины. По мере того, как становится доступным больше данных о пациентах, мы можем более подробно определять, какая информация подразумевает определенные виды лечения, ведущие к лучшим результатам для пациентов. Еще один шаг в процессе, который можно улучшить с помощью ИИ, – это общение с пациентом. Это не обязательно непосредственно сфера деятельности радиолога, однако радиологи могут предоставлять более понятные отчеты лечащему врачу, что может облегчить беседы с пациентом.
Повышение эффективности на пользу пациента
Качество медицинской помощи чрезвычайно важно, однако, если диагностика занимает слишком много времени, высокое качество бесполезно. Поэтому качество всегда нужно сочетать с эффективностью. ИИ может помочь повысить эффективность несколькими способами. Это может помочь ускорить процесс диагностики за счет автоматизации задач, выполнение которых вручную занимает много времени. Например, оценка RECIST может быть хорошим кандидатом для ускорения за счет автоматизации процесса.Другая возможность – помочь радиологу определить приоритетность неотложных случаев. Какие визуализирующие исследования рентгенолог должен оценить в первую очередь? AI может провести первую оценку и при необходимости переместить дела вверх по списку.
Будет ли ИИ работать радиологом?
Простой ответ, нет, работу радиолога он не заменит. Тем не менее, он наверняка возьмет на себя некоторые задачи радиолога. Он поможет рентгенологам выполнять автоматические измерения, которые в настоящее время отнимают очень много времени. Он будет выполнять рутинные задачи, которые многие радиологи считают обременительными.Тем не менее, у радиологов гораздо более дифференцированная работа, чем только эти задачи. Работа радиолога изменится, но никуда не исчезнет.
Как разобраться в искусственном интеллекте (ИИ) в радиологической промышленности?
Есть несколько способов взглянуть на индустрию искусственного интеллекта (ИИ) в радиологии. Один из вариантов – изучить все возможные варианты использования, с которыми может справиться ИИ. Чтобы убедиться, что мы охватили все возможности, имеет смысл сгруппировать их по модальности и участку тела (см. Рисунок 12).Другой вариант – набросать полный рабочий процесс радиологии и нарисовать все возможные способы, которыми алгоритм может творить чудеса. Это может показаться немного расплывчатым, но в следующих разделах мы рассмотрим различные способы понимания текущих концепций ИИ в радиологии.
Охватить каждый этап интегрированного рабочего процесса диагностики
В этом разделе мы обсудим рабочий процесс радиологии и рассмотрим этапы диагностической цепочки, которые могут поддерживать алгоритмы. Ниже приведены несколько примеров, использующих упрощенный обзор диагностической цепочки.
Рисунок 12. Схематический обзор диагностической цепочки, включая несколько примеров шагов, в которых алгоритмы искусственного интеллекта могут сыграть роль.
-
Радиологическое изображение в радиологический отчет
Именно здесь работает большинство компаний, представленных, например, на RSNA. Эти компании обычно разрабатывают программное обеспечение как инструмент прямой поддержки для радиолога: изображения поступают, отчеты часто выходят с количественными результатами. -
Необработанные данные сканера в рентгенологическое изображение
Применение интеллектуальных алгоритмов к необработанным данным непосредственно со сканера, например к-пространству МРТ, может быть выполнено по трем причинам.Во-первых, это может повысить качество изображения. Во-вторых, это может обеспечить понижающую выборку полученных данных, что сокращает время сканирования. В-третьих, это может сделать возможным рентгеновское излучение с более низкой дозой или компьютерную томографию. Это также называется глубокая визуализация . -
Необработанные данные сканера для отчета о радиологии
По-настоящему интересно становится, когда мы начинаем пропускать этапы диагностической цепочки. Например, это можно сделать, пропустив изображение в том виде, в каком мы его знаем, и позволив алгоритму составлять радиологические отчеты напрямую на основе необработанных данных сканирования.Это, конечно, становится сложным при выполнении быстрой проверки результатов алгоритма: человеческий мозг плохо справляется с представлениями k-пространства. Но если будет доказана надежная работа, она может поддержать радиологов, взяв на себя рутинные и трудоемкие задачи, которые в настоящее время препятствуют рабочему списку радиолога. -
Рентгенологическое изображение в отчет о патологии
Другой подход, продвигающий здравоохранение, – это получение патологической или генетической информации только на основе изображений. Алгоритм должен уметь определять особенности изображения, характеризующие различные типы опухолей, которые (пока) не могут быть различимы радиологами.В будущем этот метод может помочь предотвратить инвазивную биопсию. -
Исходные данные сканера для оценки состояния здоровья
Это как нельзя лучше приближается к святому Граалю в области медицинской визуализации: напрямую подключайте необработанные данные сканера к ожидаемому результату для здоровья. Представьте себе сканирование пациента и сразу после сканирования возможность постулировать, что этот пациент может ожидать в будущем. Конечно, помимо изображений, вам необходимо включить в набор обучающих данных другую информацию, которая необходима для разработки алгоритма.Например, возможные виды лечения, связанные с исходом, поскольку разные методы лечения, скорее всего, приведут к разным результатам.
Многие другие этапы диагностической цепочки могут поддерживаться алгоритмами AI. В будущем мы расширим этот раздел примерами исследований, иллюстрирующих другие шаги.
Вариант использования радиологии искусственного интеллекта по варианту использования
Предположим, мы хотим охватить все возможные радиологические проблемы, которые можно решить путем извлечения информации из медицинских изображений.«Пространство», которое у нас получается, мы назовем «индустрией искусственного интеллекта в радиологии». Визуально это будет выглядеть примерно так:
Рис. 13: Обзор ИИ в радиологической промышленности, выраженный в модальностях, участках тела и сценариях использования. Каждый кружок представляет один вариант использования, следовательно, это отдельный алгоритм . 10
Это вполне разумный подход. Различные методы визуализации имеют очень разные характеристики. Результатом этого является то, что вы не можете просто ожидать, что алгоритм, который был разработан для измерения объема мозга на изображениях МРТ, будет выполнять точно такой же анализ с использованием компьютерной томографии.Чтобы разработать алгоритм, который может обрабатывать оба ваших тренировочных набора данных, он должен включать как МРТ, так и компьютерную томографию. И их нужно много. Более чем в два раза больше данных, необходимых для простого алгоритма, основанного на одной модальности. Алгоритм не только должен распознавать, что является тканью мозга, а что нет, но также должен определять, имеет ли он дело с МРТ или компьютерной томографией. Чтобы иметь возможность хорошо выполнить оба анализа, алгоритму требуется больше данных, чем для ответа только на один вопрос (т.е. «Это МРТ или компьютерная томография?» или «какой объем мозга у этого пациента?»).
Дополнительно нужно учитывать разные органы. Различные органы имеют разные формы, структуры и отличаются множеством других функций, из-за чего одному алгоритму очень сложно работать с несколькими органами одновременно. Возникает та же проблема, что и при разных модальностях: объединение нескольких органов в один алгоритм требует огромного количества данных.
Нам нужно пойти еще на один уровень глубже: различные варианты использования внутри органа.Обнаружение опухоли печени – это совсем другая задача для алгоритма, чем определение количества жира в печени. Поэтому большинство компаний разрабатывают очень специфические решения для обнаружения или расчета определенного значения или характеристики в определенном органе при определенной модальности.
Вам нужно различное программное обеспечение для каждого сценария использования? Нет, не обязательно. Вы можете комбинировать разные алгоритмы в одном программном пакете и попросить радиолога выбрать вариант использования, с которым он или она имеет дело.Другой, более автоматизированный вариант – позволить программному обеспечению определить по тегам DICOM, какой тип изображения необходимо проанализировать, чтобы выбрать алгоритм, который необходимо применить.
Как внедрить ИИ в повседневную практику?
При внедрении программного обеспечения AI вы начинаете с оценки того, какой тип программного обеспечения вам нужен. Как только вы узнаете, чего хотите, вы можете начать реальный процесс внедрения, чтобы запустить программное обеспечение. Насколько это сложно, во многом зависит от типа программного обеспечения и от того, хотите ли вы интегрировать его в другое программное обеспечение, которое у вас уже есть на сайте.Поэтому при выборе программного обеспечения для искусственного интеллекта важно подумать над следующими вопросами.
Облачная служба или на месте?
Прежде чем говорить об интеграции, важно уточнить требования больницы к безопасности данных. Могут ли снимки пациента покидать институт или они должны оставаться в помещении? Если ваша больница может отправлять анонимные отсканированные изображения внешней стороне, вы можете использовать интеграцию облачной службы. Многие радиологические компании с искусственным интеллектом предлагают облачные сервисы, требующие от вас отправки сканированных изображений, и они выполняют обработку за вас за вас.Однако имейте в виду, что вы зависите от времени их выполнения, к тому же обычно нет возможности изменить полученные результаты. Вы должны включать их в свои отчеты как есть, в лучшем случае вы можете добавить несколько комментариев.
Автономная рабочая станция или плавающая лицензия?
Самым простым локальным решением является автономная рабочая станция. Программное обеспечение AI устанавливается на один компьютер, которым могут пользоваться все пользователи. Если в вашей больнице много конкретных случаев, это может быть хорошим решением.Или, если рентгенологи могут использовать программное обеспечение для предубеждения. Однако чаще всего предпочтительнее решение с плавающей лицензией. Это решение позволяет врачам получать доступ к программному обеспечению с нескольких компьютеров.
Интеграция с другими поставщиками радиологии?
Для многих больниц это предпочтительный вариант. И не без причины: это избавляет от множества хлопот, поскольку об интеграции в рабочий процесс заботятся другие стороны, такие как компания-разработчик программного обеспечения ИИ и другой вовлеченный поставщик радиологии (например,г. компания PACS). Единственное, что нужно сделать больнице, – это активировать подключаемый модуль в своей системе PACS, программе распознавания голоса, расширенном средстве просмотра или любом другом уже установленном программном обеспечении для радиологии. Важно дважды проверить, есть ли другие условия. Например, если программное обеспечение требует автоматической пересылки, можно ли это легко включить в PACS?
С другой стороны, этот сценарий довольно сложен для отрасли. Реализация интеграции может занять много времени, и ни один поставщик не похож.Это означает, что интеграция с поставщиком PACS X не обязательно является копи-вставкой по сравнению с интеграцией с поставщиком PACS Y. Другими словами, у компаний, занимающихся ИИ, есть довольно длинный и трудоемкий список дел, когда дело доходит до усилий по интеграции. Например, прочтите наш блог о 5 вариантах интеграции искусственного интеллекта на основе изображений в рабочий процесс радиологии.
Промежуточное решение – использование платформ. Эти брокерские стороны собирают на своей платформе несколько алгоритмов от разных компаний, занимающихся ИИ, и предлагают полный пакет больницам.Некоторые из них интегрируются с другими поставщиками радиологии, другие просто объединяют партнерские компании, занимающиеся ИИ, в одной цифровой среде. Основная идея заключается в том, что вам не нужно иметь дело с разными компаниями, занимающимися ИИ, а только с одной компанией-платформой.
Сейчас или позже?
Важный вопрос: хочет ли ваше радиологическое отделение внедрить технологию искусственного интеллекта сейчас или позже? Конечно, можно дождаться, пока не закончатся проблемы с прорезыванием зубов. Тем не менее, внедрение технологии искусственного интеллекта дает конкретные преимущества.Вы можете принять участие в этих изменениях, повлиять на разработку программного обеспечения искусственного интеллекта и убедиться, что оно наилучшим образом соответствует потребностям радиологов. Вы привлекаете новые таланты, желающие работать с технологиями искусственного интеллекта. Кроме того, многие компании, занимающиеся ИИ, ищут партнеров для клинических исследований. Это может быть вашим шансом поработать над интересными исследовательскими проектами или получить скидки, потому что вы – один из первых пользователей, желающих первым пробовать (а иногда и тестировать) новое программное обеспечение. И, скорее всего, лучшая причина: ИИ действительно добавляет ценности.Либо взяв на себя рутинные задачи, сделав более дифференцированную диагностику, ускорив процесс, 11 или повысив точность диагностики. Что, в конце концов, приведет к лучшим результатам для пациентов. У искусственного интеллекта есть все возможности стать величайшим активом, доступным современному радиологу.
Каковы текущие проблемы ИИ в радиологии?
Кажется, нет предела возможностей применения ИИ в радиологии. Но пока есть еще немало проблем, которые необходимо преодолеть, прежде чем ИИ будет широко применяться и полностью адаптирован в рабочем процессе радиологии, некоторые из которых мы обсудим ниже.
Достаточное количество данных с маркировкой качества
В области медицины получить доступ к большим высококачественным наборам данных для обучения непросто. Другие общие базы данных чрезвычайно мощны, потому что они включают огромное количество изображений, которые точно помечены. Сравнивая типичный набор данных медицинской визуализации, состоящий примерно из 1000 изображений, с немедицинской базой данных, которая может содержать до 100 000 000 изображений, можно только сделать вывод, что доступный объем явно все еще на несколько порядков меньше.Способ преодоления этой проблемы – использование аугментации.
Рисунок 14: Большие данные могут состоять из многих различных типов данных.
Работа с трехмерной реальностью
Наиболее успешные модели глубокого обучения в настоящее время обучаются на простых 2D-изображениях. КТ- и МРТ-изображения обычно бывают трехмерными, что добавляет проблеме дополнительное измерение. Обычные рентгеновские изображения могут быть двухмерными, однако из-за их проецируемого характера большинство текущих алгоритмов глубокого обучения также не адаптированы к этим изображениям.Необходимо получить опыт применения глубокого обучения к этим типам изображений.
Получение нестандартных изображений
Различные типы сканеров, разные настройки сбора данных… Нестандартное получение медицинских изображений создает сложную ситуацию для обучения алгоритмов искусственного интеллекта. Чем больше разнообразия в данных, тем больше должен быть набор данных, чтобы сеть глубокого обучения приводила к надежному алгоритму. Один из способов преодоления этого барьера – применить трансферное обучение, которое представляет собой метод предварительной обработки, направленный на преодоление специфики сканера и сбора данных.
Удобный пользовательский интерфейс
Один из наиболее частых комментариев радиологов касается их неудовлетворительного опыта работы с текущим программным обеспечением для радиологии. Почему? Потому что это, как правило, очень недружелюбно для пользователя. Это требует слишком много времени ожидания, слишком много щелчков мышью, и как только вы войдете в программу, вы не сможете жить без руководства.
Создание удобного программного обеспечения – необходимость для компаний, занимающихся ИИ, которые хотят, чтобы их программное обеспечение использовалось в клинике. Однако это не так просто, как кажется.Многие приложения разрабатываются в первую очередь на основе технологий, то есть компания начинает с алгоритма, а затем превращает его в продукт. Это не обязательно плохой подход, вы уверены, что у вас есть рабочий алгоритм, но проверка удобства использования вашего продукта должна быть частью процесса разработки продукта, желательно с самого начала, чтобы радиологи начали и продолжали используя его в клинике.
Рис. 15. Приложения искусственного интеллекта должны обеспечивать беспроблемное взаимодействие с пользователем, способствуя их принятию.
Бизнес-пример, который в сумме дает
Как будет развиваться финансовая картина? Придется ли больницам выделять бюджет? Будет ли в конечном итоге выставлен счет пациенту? Или, согласно сценарию, к которому мы стремимся, будет ли ИИ окупаться? Маловероятно, что программное обеспечение для радиологии ИИ в его текущем состоянии сможет полностью поддерживать себя, в основном из-за предварительных инвестиций, которые необходимо сделать. В этой ситуации очевидно только то, что инвестор хочет знать, чего ожидать в долгосрочной перспективе, поэтому компаниям, занимающимся ИИ, необходимо иметь четкое представление о том, как их программное обеспечение принесет финансовую пользу больницам в будущем: сэкономит ли это время врачей? Сможет ли больница сократить время ожидания и тем самым помочь большему количеству пациентов? Повысится ли точность диагностики и приведет ли к экономии на более позднем этапе процесса? Есть ли коды возмещения для конкретного анализа? Ответы будут различаться в зависимости от сценария использования и географического положения, что делает это обширным упражнением, но для того, чтобы убедить больницы (и другие участвующие стороны), компаниям, занимающимся ИИ, крайне важно иметь четкое экономическое обоснование.
Правильные показатели производительности
Каждый ученый подтвердит, что вам необходимо четко понимать, что вы измеряете, как вы это измеряете и, что, вероятно, наиболее важно, почему вы это измеряете. ИИ в радиологии ничем не отличается от любой другой области исследований. Компаниям, занимающимся ИИ, необходимо четко определять свои показатели эффективности. Часто используемые показатели – это точность, точность, отзывчивость и т. Д. Однако эти показатели не всегда применимы. Точность рассчитывается с использованием количества истинно положительных, истинно отрицательных, ложных и ложно отрицательных результатов.В случае автоматической сегментации нет прямой интерпретации истинно положительного или ложноотрицательного. Следовательно, выбор метрики имеет первостепенное значение, если вы хотите нарисовать правильную картину того, как работает ваше программное обеспечение.
Вскоре мы обновим этот раздел, добавив в него различные типы доступных показателей производительности и примеры их применения.
Доверие пользователей к радиологии AI
Однако, возможно, самая важная проблема, с которой сталкиваются радиологические компании, занимающиеся ИИ, – это отсутствие доверия к искусственному интеллекту, когда дело доходит до ответов на вопросы, связанные с анализом медицинских изображений.ИИ часто рассматривается как «черный ящик», о котором неясно, как именно он пришел к своему ответу. Как мы можем упростить внедрение ИИ и укрепить доверие пользователей? Это можно сделать несколькими способами: с помощью научных исследований, установки программного обеспечения в больнице и тестового запуска приложения. Другой пример, предложенный исследователями в 2018 году, – позволить алгоритму отображать аналогичные случаи из набора обучающих данных, чтобы дать врачам больше информации о том, какие данные использовались для получения определенного понимания. 12 Если компании, работающие с ИИ, хотят выжить в области радиологии, они должны инвестировать в завоевание доверия пользователей.
Библиография
- 10-минутная история радиологии: обзор монументальных изобретений. (2017). Доступно по адресу: https://www.bicrad.com/blog/2017/6/9/10-minute-history-of-radiology-overview-of-monumental-inventions. (Дата обращения: 4 марта 2019 г.)
- Chartrand, G. et al. Глубокое обучение: учебник для радиологов. RadioGraphics 37, 2113–2131 (2017).
- Hacking, C. & Pai, V. Kellgren и Система Лоуренса для классификации остеоартроза коленного сустава. Доступно по адресу: https://radiopaedia.org/articles/kellgren-and-lawrence-system-for-classification-of-osteoarthritis-of-knee. (Дата обращения: 4 марта 2019 г.)
- Эриксон, Б. Дж., Корфиатис, П., Аккус, П. и Клайн, Т. Л. Машинное обучение для медицинской визуализации. RadioGraphics 37, 505–515 (2017).
- Что такое машинное обучение? Доступно по адресу: https: // nl.mathworks.com/discovery/machine-learning.html. (Дата обращения: 4 марта 2019 г.)
- Пейкари, М., Салама, С., Нофек-Мозес, С. и Мартель, А. Л. Кластерный полууправляемый подход к обучению для классификации патологических образов. Nat. Sci. Отчеты 8, (2018).
- Пупале, Р. Машины опорных векторов (SVM) – Обзор. (2018). Доступно по адресу: https://towardsdatascience.com/https-medium-com-pupalerushikesh-svm-f4b42800e989. (Дата обращения: 4 марта 2019 г.)
- Кошик, С.Введение в кластеризацию и различные методы кластеризации. (2016). Доступно по адресу: https://www.analyticsvidhya.com/blog/2016/11/an-introduction-to-clustering-and-different-methods-of-clustering. (Дата обращения: 4 марта 2019 г.)
- Руководство по нейронным сетям и глубокому обучению для новичков. Доступно по адресу: https://skymind.ai/wiki/neural-network. (Дата обращения: 4 марта 2019 г.)
- Дрейер, К. Использование искусственного интеллекта в здравоохранении. (2017). Доступно по адресу: http://on-demand.gputechconf.com/gtc/2017/video/s7840-dr-keith-dreyer-harnessing-ai-in-healthcare.mp4. (Дата обращения: 5 марта 2019 г.)
- Ridley, E.L. Алгоритм AI может упорядочивать КТ-исследования головы для срочной проверки. (2018). Доступно по адресу: https://www.auntminnie.com/index.aspx?sec=sup&sub=aic&pag=dis&ItemID=120662. (Дата обращения: 6 сентября 2018 г.)
- Ridley, E. L. Новый алгоритм решает проблемы искусственного интеллекта. (2018). Доступно по адресу: https://www.auntminnie.com/index.aspx?sec=sup&sub=aic&pag=dis&ItemID=124063. (Дата обращения: 4 марта 2019 г.)
Основы машинного обучения: исчисление I: ограничения и производные
Серия онлайн-тренингов «Основы машинного обучения» дает всесторонний обзор всех предметов – математики, статистики и информатики – которые лежат в основе современных методов машинного обучения, включая глубокое обучение и другие подходы к искусственному интеллекту.
Все классы этой серии воплощают теорию в жизнь благодаря сочетанию ярких полноцветных иллюстраций, простых примеров Python в практических демонстрациях блокнотов Jupyter и упражнений на понимание с полностью проработанными решениями.
Основное внимание уделяется предоставлению вам практического и функционального понимания охваченного содержания. Для каждой темы будет дан контекст, подчеркивающий ее актуальность для машинного обучения. У вас будет больше возможностей для понимания передовых документов по машинному обучению, и вам будут предоставлены ресурсы для более глубокого изучения тем, которые вызывают ваше любопытство.
Восемь классов в серии организованы в четыре куплета:
Линейная алгебра
Исчисление
Статистика
Информатика
Содержание второго класса каждого куплета следует непосредственно из содержания первого, однако вы можете выбирать между любыми отдельными классами, исходя из ваших конкретных интересов или вашего существующего знакомства с материалом.(Обратите внимание, что в любой момент времени только часть этих занятий будет запланирована и открыта для регистрации. Чтобы получать уведомления о предстоящих занятиях в этой серии, подпишитесь на электронную рассылку инструкторов на jonkrohn.com.)
Этот класс x знакомит с математической областью исчисления – изучением темпов изменения – с нуля. Это важно, потому что вычисление производных через дифференцирование является основой оптимизации большинства алгоритмов машинного обучения, в том числе используемых в глубоком обучении, таких как обратное распространение и стохастический градиентный спуск.Благодаря взвешенному изложению теории в сочетании с интерактивными примерами вы разовьете рабочее понимание того, как исчисление используется для вычисления пределов и дифференцирования функций. Вы также узнаете, как применять автоматическое дифференцирование в популярных библиотеках машинного обучения TensorFlow 2 и PyTorch. Содержание этого класса само по себе является основополагающим для нескольких других классов из серии Machine Learning Foundations , особенно Calculus II и Optimization .
Новый бизнес искусственного интеллекта (и чем он отличается от традиционного программного обеспечения)
На техническом уровне кажется, что будущее программного обеспечения – за искусственным интеллектом. Искусственный интеллект демонстрирует заметный прогресс в решении ряда сложных проблем информатики, и работа разработчиков программного обеспечения, которые теперь работают с данными не меньше, чем с исходным кодом, в процессе коренным образом меняется.
Многие AI-компании (и инвесторы) делают ставку на то, что эти отношения будут выходить за рамки только технологий – что AI бизнес также будет напоминать традиционные компании-разработчики программного обеспечения.Судя по нашему опыту работы с компаниями, занимающимися ИИ, мы в этом не уверены.
Мы твердо верим в способность ИИ трансформировать бизнес: мы вложили деньги в этот тезис и продолжим инвестировать значительные средства как в компании, занимающиеся прикладным ИИ, так и в инфраструктуру ИИ. Однако во многих случаях мы заметили, что компании, занимающиеся ИИ, просто не имеют такой экономической конструкции, как компании, занимающиеся разработкой программного обеспечения. Иногда они могут даже больше походить на традиционные сервисные компании. В частности, у многих AI-компаний есть:
- Более низкая валовая прибыль из-за интенсивного использования облачной инфраструктуры и постоянной поддержки со стороны персонала;
- Проблемы масштабирования из-за сложной проблемы крайних случаев;
- Более слабые защитные рвы из-за коммерциализации моделей искусственного интеллекта и проблем с эффектами сети передачи данных.
Как ни странно, мы наблюдали удивительно последовательную закономерность в финансовых данных компаний, занимающихся ИИ, с валовой прибылью часто в диапазоне 50–60%, что значительно ниже контрольного показателя 60–80% + для сопоставимых предприятий SaaS. Частный капитал на ранней стадии может скрыть эту неэффективность в краткосрочной перспективе, особенно когда некоторые инвесторы стремятся к росту, а не к прибыльности. Однако неясно, может ли любая долгосрочная оптимизация продукта или вывода на рынок (GTM) полностью решить проблему.
Подобно тому, как SaaS открыла новую экономическую модель по сравнению с локальным программным обеспечением, мы считаем, что AI создает принципиально новый тип бизнеса . В этом посте рассматриваются некоторые отличия компаний, занимающихся ИИ, от традиционных компаний, производящих программное обеспечение, и дается несколько советов о том, как устранить эти различия. Наша цель состоит не в том, чтобы давать предписания, а в том, чтобы помочь операторам и другим лицам понять экономику и стратегический ландшафт ИИ, чтобы они могли создавать устойчивые компании.
Мы замечали, что во многих случаях компании, занимающиеся ИИ, просто не имеют такой экономической конструкции, как компании, занимающиеся разработкой программного обеспечения.Иногда они могут даже больше походить на традиционные сервисные компании. Нажмите, чтобы твитнутьПрограммное обеспечение + услуги = AI?
Прелесть программного обеспечения (включая SaaS) в том, что его можно создать один раз и продать много раз. Это свойство создает ряд неоспоримых преимуществ для бизнеса, включая повторяющиеся потоки доходов, высокую (60-80% +) валовую прибыль и – в относительно редких случаях, когда применяются сетевые эффекты или эффекты масштаба – суперлинейное масштабирование . У компаний-разработчиков программного обеспечения также есть потенциал для создания прочных защитных рвов, поскольку они владеют интеллектуальной собственностью (обычно кодом), созданной в результате их работы.
Сервисные компании занимают другой конец спектра. Каждый новый проект требует специального персонала и может быть продан ровно один раз. В результате доход, как правило, является единовременным, валовая прибыль ниже (30–50%), а масштабирование в лучшем случае является линейным. Защита более сложна – часто основанная на бренде или действующем контроле учетной записи – потому что любой IP, не принадлежащий клиенту, вряд ли будет иметь широкое применение.
компаний, занимающихся ИИ, все чаще объединяют в себе элементы программного обеспечения и услуг.
Большинство приложений ИИ выглядят как обычные программы. Они полагаются на обычный код для выполнения таких задач, как взаимодействие с пользователями, управление данными или интеграция с другими системами. Однако в основе приложения лежит набор обученных моделей данных. Эти модели интерпретируют изображения, расшифровывают речь, генерируют естественный язык и выполняют другие сложные задачи. Иногда их обслуживание может больше походить на бизнес по оказанию услуг – требующий значительных, ориентированных на клиента работ и затрат, выходящих за рамки типичных функций поддержки и обеспечения успеха.
Эта динамика влияет на бизнес, связанный с искусственным интеллектом, по ряду важных направлений. В следующих разделах мы исследуем некоторые из них – валовую прибыль, масштабирование и защищаемость.
Компании, занимающиеся ИИ, все чаще объединяют элементы программного обеспечения и услуг с валовой прибылью, масштабированием и защитой, что может полностью представлять новый класс бизнеса. Нажмите, чтобы твитнутьВаловая прибыль, Часть 1: Облачная инфраструктура – существенные, а иногда и скрытые расходы для компаний, занимающихся ИИ
В старые времена, когда программное обеспечение было локальным, доставка продукта означала уничтожение и отправку физических носителей – расходы на запуск программного обеспечения, будь то на серверах или настольных компьютерах, ложились на покупателя.Сегодня, когда преобладает SaaS, эта стоимость возложена на поставщика. Большинство компаний-разработчиков программного обеспечения оплачивают большие счета за использование AWS или Azure каждый месяц – чем выше требования к программному обеспечению, тем выше счет.
AI, оказывается, довольно требователен:
- Обучение одна модель ИИ может стоить сотни тысяч долларов (или больше) в вычислительных ресурсах . Хотя заманчиво рассматривать это как единовременные расходы, переподготовка все чаще признается в качестве постоянных затрат, поскольку данные, которые используются в моделях ИИ, имеют тенденцию меняться со временем (явление, известное как «дрейф данных»).
- Вывод модели (процесс создания прогнозов в производстве) также является более сложным с точки зрения вычислений, чем работа с традиционным программным обеспечением. Выполнение длинной серии умножений матриц требует больше математических вычислений, чем, например, чтение из базы данных.
- AI-приложения с большей вероятностью, чем традиционное программное обеспечение, будут работать с Rich Media , такими как изображения, аудио или видео. Эти типы данных потребляют больше, чем обычно ресурсов хранилища , дороги в обработке и часто страдают от проблем области интереса – приложению может потребоваться обработать большой файл, чтобы найти небольшой релевантный фрагмент.
- У нас были компании, занимающиеся ИИ, которые рассказывали нам, что облачные операции могут быть более сложными и дорогостоящими, чем традиционные подходы, особенно потому, что нет хороших инструментов для глобального масштабирования моделей ИИ. В результате некоторым компаниям, занимающимся ИИ, приходится регулярно переносить обученные модели в облачные регионы, что требует больших затрат на входящие и исходящие данные, для повышения надежности, задержки и соответствия требованиям.
В совокупности эти факторы обеспечивают 25% или более доходов, которые компании, занимающиеся ИИ, часто тратят на облачные ресурсы.В крайних случаях стартапы, решающие особо сложные задачи, фактически обнаружили, что ручная обработка данных дешевле, чем выполнение обученной модели.
Помощьприходит в виде специализированных ИИ-процессоров, которые могут выполнять вычисления более эффективно, и методов оптимизации, таких как сжатие моделей и кросс-компиляция, которые сокращают количество необходимых вычислений.
Но не совсем ясно, как будет выглядеть кривая эффективности. Во многих проблемных областях требуется экспоненциально больше обработки и данных для постепенного повышения точности.Это означает, как мы уже отмечали ранее, что сложность модели растет с невероятной скоростью, и маловероятно, что процессоры смогут с ней справиться. Закона Мура недостаточно. (Например, вычислительные ресурсы, необходимые для обучения современных моделей искусственного интеллекта, выросли более чем в 300000 раз с 2012 года, в то время как количество транзисторов графических процессоров NVIDIA выросло всего в ~ 4 раза!) Распределенные вычисления – убедительное решение этой проблемы. , но в первую очередь речь идет о скорости, а не о стоимости.
Валовая прибыль, часть 2: Многие приложения искусственного интеллекта полагаются на «людей в петле» для работы с высоким уровнем точности
Системы Human-in-the-loop бывают двух форм, каждая из которых способствует снижению валовой прибыли для многих стартапов в области ИИ.
Первое: обучение большей части современных моделей искусственного интеллекта включает ручную очистку и маркировку больших наборов данных. Этот процесс трудоемкий, дорогостоящий и является одним из самых больших препятствий на пути более широкого внедрения ИИ. Кроме того, как мы обсуждали выше, обучение не заканчивается после развертывания модели. Чтобы поддерживать точность, новые данные обучения необходимо постоянно собирать, маркировать и отправлять обратно в систему. Хотя такие методы, как обнаружение дрейфа и активное обучение, могут снизить нагрузку, неофициальные данные показывают, что многие компании тратят до 10-15% дохода на этот процесс – обычно не считая основных инженерных ресурсов – и предполагают, что текущая работа по разработке превышает типичные исправления ошибок и функции. дополнения.
Вторая: для многих задач, особенно тех, которые требуют более глубокого мышления, люди часто подключаются к системам искусственного интеллекта в режиме реального времени. Компании социальных сетей, например, нанимают тысячи людей-рецензентов для расширения систем модерации на основе искусственного интеллекта. Многие автономные автомобильные системы включают в себя удаленных людей-операторов, а большинство медицинских устройств на основе ИИ взаимодействуют с врачами в качестве лиц, принимающих совместные решения. Все больше и больше стартапов применяют этот подход, поскольку возможности современных систем искусственного интеллекта становятся все более понятными.Ряд компаний, занимающихся искусственным интеллектом, которые планировали продавать чисто программные продукты, все чаще предлагают собственные услуги и покрывают связанные с этим расходы.
Потребность в человеческом вмешательстве, вероятно, уменьшится по мере повышения производительности моделей искусственного интеллекта. Однако маловероятно, что люди будут полностью исключены из цикла. Многие проблемы – например, беспилотные автомобили – слишком сложны, чтобы их можно было полностью автоматизировать с помощью технологий искусственного интеллекта текущего поколения. Вопросы безопасности, справедливости и доверия также требуют значимого человеческого надзора – факт, который, вероятно, будет закреплен в правилах ИИ, которые в настоящее время разрабатываются в США, ЕС и других странах.
Потребность в человеческом вмешательстве, вероятно, уменьшится по мере повышения производительности моделей искусственного интеллекта. Однако маловероятно, что люди будут полностью исключены из цикла. Нажмите, чтобы твитнутьДаже если в конечном итоге мы добьемся полной автоматизации для определенных задач, неясно, насколько увеличится прибыль в результате. Основная функция приложения AI – обрабатывать поток входных данных и генерировать соответствующие прогнозы. Таким образом, стоимость эксплуатации системы зависит от объема обрабатываемых данных.Некоторые точки данных обрабатываются людьми (относительно дорого), в то время как другие обрабатываются автоматически моделями ИИ (надеюсь, дешевле). Но каждый ввод нужно обрабатывать так или иначе.
По этой причине две категории затрат, которые мы обсуждали до сих пор, – облачные вычисления и человеческая поддержка – фактически связаны. Уменьшение одного обычно приводит к увеличению другого. Обе части уравнения можно оптимизировать, но ни одна из них вряд ли достигнет почти нулевого уровня затрат, присущего SaaS-бизнесу.
Масштабирование систем ИИ может оказаться более нестабильным, чем ожидалось, потому что ИИ живет в длинном хвосте
Для компаний, занимающихся искусственным интеллектом, узнать, когда вы нашли продукт, соответствующий рынку, немного сложнее, чем с традиционным программным обеспечением. Обманчиво легко думать, что вы достигли цели – особенно после закрытия 5–10 крупных клиентов – только для того, чтобы увидеть, как объем невыполненной работы вашей команды ML начинает раздуваться, а графики развертывания клиентов начинают зловеще растягиваться, отвлекая ресурсы от новых продаж.
Во многих ситуациях виноваты крайние случаи. Многие приложения ИИ имеют открытые интерфейсы и работают с зашумленными, неструктурированными данными (например, изображениями или естественным языком). Пользователям часто не хватает интуиции в отношении продукта или, что еще хуже, они предполагают, что он обладает человеческими / сверхчеловеческими способностями. Это означает, что крайние случаи есть повсюду: от 40 до 50% предполагаемой функциональности продуктов ИИ, которые мы рассмотрели, могут находиться в длинном хвосте намерений пользователя.
Другими словами, пользователи могут – и будут – вводить что угодно в приложение AI.
Пользователи могут – и будут – вводить что угодно в приложение AI. Нажмите, чтобы твитнутьРабота с этим огромным пространством состояний обычно является постоянной рутиной. Поскольку диапазон возможных входных значений очень велик, каждое развертывание нового клиента, вероятно, будет генерировать данные, которые ранее не были доступны. Даже клиенты, которые кажутся похожими – например, два производителя автомобилей, занимающиеся обнаружением дефектов, – могут нуждаться в существенно разных обучающих данных из-за такой простой вещи, как размещение видеокамер на их сборочных линиях.
Один из основателей называет это явление «временной ценой» продуктов ИИ. Ее компания проводит специальный период сбора данных и точной настройки модели в начале каждого нового взаимодействия с клиентом. Это дает им возможность видеть распределение данных клиентов и устраняет некоторые крайние случаи до развертывания. Но это также влечет за собой затраты: команда и финансовые ресурсы компании связаны до тех пор, пока точность модели не достигнет приемлемого уровня. Продолжительность периода обучения также обычно неизвестна, поскольку обычно существует несколько вариантов для более быстрого создания обучающих данных… независимо от того, насколько усердно работает команда.
ИИ-стартапы часто в конечном итоге тратят больше времени и ресурсов на развертывание своих продуктов, чем они ожидали. Заблаговременно определить эти потребности может быть сложно, поскольку традиционные инструменты прототипирования, такие как макеты, прототипы или бета-тесты, обычно охватывают только наиболее распространенные пути, а не крайние случаи. Как и в случае с традиционным программным обеспечением, этот процесс особенно трудоемок для самых первых когорт клиентов, но, в отличие от традиционного программного обеспечения, он не обязательно исчезает со временем.
Пособие по защите бизнеса, связанного с ИИ, все еще создается
Великие компании-разработчики программного обеспечения строятся вокруг прочных защитных рвов.Некоторые из лучших факторов – это сильные факторы, такие как сетевые эффекты, высокие затраты на переключение и экономия на масштабе.
Все эти факторы возможны и для компаний, занимающихся ИИ. Основа защищенности обычно формируется – особенно на предприятии – технически более совершенным продуктом. Быть первым, кто внедрит сложное программное обеспечение, может дать бренду значительные преимущества и периоды почти эксклюзивности.
В мире искусственного интеллекта труднее достичь технической дифференциации.Архитектура новых моделей разрабатывается в основном в открытых академических условиях. Эталонные реализации (предварительно обученные модели) доступны из библиотек с открытым исходным кодом, а параметры модели могут быть оптимизированы автоматически. Данные – это ядро системы искусственного интеллекта, но они часто принадлежат клиентам, являются общественным достоянием или со временем становятся товаром. Он также имеет уменьшающуюся ценность по мере созревания рынков и демонстрирует относительно слабые сетевые эффекты. В некоторых случаях мы даже наблюдали убытков от масштабов, связанных с информационным наполнением предприятий искусственного интеллекта.По мере того, как модели становятся более зрелыми, как утверждается в «Пустом обещании рвов данных», каждый новый пограничный случай становится все более и более дорогостоящим для решения, обеспечивая при этом ценность для все меньшего и меньшего числа релевантных клиентов.
Это не обязательно означает, что продукты ИИ менее защищены, чем их чисто программные аналоги. Но рвы для компаний, занимающихся ИИ, оказались меньше, чем многие ожидали. С точки зрения защиты ИИ может быть в значительной степени сквозным каналом для основных продуктов и данных.
Это не обязательно означает, что продукты ИИ менее защищены, чем их чисто программные аналоги.Но рвы для компаний, занимающихся ИИ, оказались меньше, чем многие ожидали. Нажмите, чтобы твитнутьСоздание, масштабирование и защита великих AI-компаний – практические советы для основателей
Мы считаем, что ключом к долгосрочному успеху компаний, занимающихся ИИ, является умение решать проблемы и сочетать лучшее из услуг и программного обеспечения. В этом ключе, вот несколько шагов, которые основатели могут предпринять, чтобы преуспеть с новыми или существующими приложениями ИИ.
Как можно больше исключить сложность модели . Мы заметили огромную разницу в COGS между стартапами, которые обучают уникальную модель для каждого клиента, и теми, которые могут использовать одну модель (или набор моделей) для всех клиентов. Стратегию «единой модели» легче поддерживать, быстрее внедрять для новых клиентов и поддерживать более простую и эффективную инженерную организацию. Это также имеет тенденцию сокращать разрастание конвейера данных и дублирование тренировок, что может значительно снизить затраты на облачную инфраструктуру. Хотя для достижения этого идеального состояния нет серебряной пули, один из ключей – это как можно больше понимать своих клиентов – и их данные – до того, как согласится на сделку.Иногда очевидно, что новый клиент приведет к серьезной развилке ваших усилий по машинному обучению. В большинстве случаев изменения более тонкие, включают только несколько уникальных моделей или некоторую тонкую настройку. Принятие этих суждений – компромисс между долгосрочным экономическим здоровьем и краткосрочным ростом – одна из самых важных задач, с которыми сталкиваются основатели ИИ.
Тщательно – и часто узко – выбирайте проблемные области, чтобы снизить сложность данных . Автоматизация человеческого труда – это принципиально сложная задача.Многие компании обнаруживают, что минимально жизнеспособная задача для моделей искусственного интеллекта уже, чем они ожидали. Например, вместо того, чтобы предлагать общие текстовые предложения, некоторые команды добились успеха, предлагая короткие предложения по электронной почте или в объявлениях о вакансиях. Компании, работающие в сфере CRM, нашли очень ценные ниши для ИИ, основанные только на обновлении записей. Существует большой класс подобных задач, которые сложно решить людям, но относительно легко для ИИ. Они, как правило, включают в себя крупномасштабные и несложные задачи, такие как модерация, ввод / кодирование данных, транскрипция и т. Д.Сосредоточение внимания на этих областях может свести к минимуму проблему постоянных крайних случаев – другими словами, они могут упростить данные, необходимые для процесса разработки ИИ.
Мы считаем, что ключом к долгосрочному успеху компаний, занимающихся ИИ, является умение решать проблемы и сочетать лучшее из услуг и программного обеспечения. Нажмите, чтобы твитнутьПлан для высоких переменных затрат. Как основатель, у вас должна быть надежная, интуитивно понятная ментальная основа для вашей бизнес-модели. Затраты, обсуждаемые в этом посте, вероятно, улучшатся – уменьшатся на некоторую постоянную – но было бы ошибкой предполагать, что они исчезнут полностью (или форсировать это неестественным образом).Вместо этого мы предлагаем построить бизнес-модель и стратегию GTM с учетом более низкой валовой прибыли. Несколько хороших советов от основателей: глубоко разберитесь в распределении данных, используемых в ваших моделях. Рассматривайте обслуживание модели и аварийное переключение персонала как проблемы первого порядка. Отслеживайте и измеряйте свои реальные переменные затраты – не позволяйте им прятаться в исследованиях и разработках. Делайте консервативные предположения об экономике единицы в своих финансовых моделях, особенно во время сбора средств. Не ждите, пока масштабы или технический прогресс решат проблему.
Обнять услуги. Есть огромные возможности выйти на рынок там, где он есть. Это может означать предложение услуги полного перевода вместо программного обеспечения для перевода или запуск службы такси, а не продажу беспилотных автомобилей. Создание гибридного бизнеса сложнее, чем чистое программное обеспечение, но такой подход может обеспечить глубокое понимание потребностей клиентов и привести к появлению быстрорастущих, определяющих рынок компаний. Услуги также могут быть отличным инструментом для запуска механизма вывода компании на рынок (подробнее об этом см. В этом посте), особенно при продаже сложных и / или совершенно новых технологий.Ключ в том, чтобы целенаправленно следовать одной стратегии, а не поддерживать заказчиков программного обеспечения и услуг.
План изменений в стеке технологий. Современный ИИ все еще находится в зачаточном состоянии. Инструменты, которые помогают практикам выполнять свою работу эффективным и стандартизированным способом, только сейчас создаются. В течение следующих нескольких лет мы ожидаем увидеть широкую доступность инструментов для автоматизации обучения моделей, повышения эффективности вывода, стандартизации рабочих процессов разработчиков, а также мониторинга и защиты моделей искусственного интеллекта в производственной среде.Облачные вычисления в целом также привлекают все больше внимания как проблема затрат, которую должны решать компании-разработчики программного обеспечения. Тесная привязка приложения к текущему способу работы может привести к архитектурным недостаткам в будущем.
Укрепляйте обороноспособность по старинке. Хотя неясно, обеспечит ли сама модель ИИ – или лежащие в основе данные – долгосрочную основу, хорошие продукты и собственные данные почти всегда помогают построить хороший бизнес. AI дает основателям новый взгляд на старые проблемы.Например, методы искусственного интеллекта принесли новую пользу на относительно спящем рынке обнаружения вредоносных программ, просто продемонстрировав более высокую производительность. Возможность создавать устойчивые продукты и устойчивый бизнес на основе первоначальных уникальных возможностей продукта вечна. Интересно, что мы также видели, как несколько компаний, занимающихся ИИ, укрепили свои позиции на рынке с помощью эффективной облачной стратегии, аналогичной последнему поколению компаний с открытым исходным кодом.
* * *
Подводя итог: большинство систем искусственного интеллекта сегодня – это не , а программное обеспечение в традиционном смысле.И в результате бизнесы, связанные с искусственным интеллектом, не выглядят в точности как компании, занимающиеся разработкой программного обеспечения. Они включают постоянную поддержку персонала и переменные материальные затраты. Часто их не так легко масштабировать, как хотелось бы. И сильная защита, критически важная для модели программного обеспечения «построить один раз / продать много раз», похоже, не дается бесплатно.
Эти черты заставляют ИИ чувствовать себя в некоторой степени как бизнес в сфере услуг. Другими словами: вы можете заменить фирму, оказывающую услуги, но не можете (полностью) заменить услуги.
Хотите верьте, хотите нет, но это может быть хорошей новостью.Такие вещи, как переменные затраты, динамика масштабирования и защитные рвы, в конечном итоге определяются рынками, а не отдельными компаниями. Тот факт, что мы видим в данных незнакомые закономерности, говорит о том, что компании, занимающиеся ИИ, действительно являются чем-то новым – они выходят на новые рынки и создают огромные возможности. Уже есть ряд великих компаний, занимающихся ИИ, которые успешно преодолели лабиринт идей и создали продукты с неизменно высокой производительностью.
Такие вещи, как переменные затраты, динамика масштабирования и защитные рвы, в конечном итоге определяются рынками, а не отдельными компаниями.Тот факт, что мы видим незнакомые закономерности в данных, говорит о том, что компании, занимающиеся ИИ, действительно являются чем-то новым … Нажмите, чтобы твитнутьAI все еще находится на ранней стадии перехода от темы исследования к производственной технологии. Легко забыть, что AlexNet, которая, возможно, положила начало нынешней волне разработки программного обеспечения ИИ, была опубликована менее восьми лет назад. Интеллектуальные приложения продвигают индустрию программного обеспечения вперед, и мы очень рады видеть, в каком направлении они пойдут дальше.
–
Источники: Оценка валовой прибыли для традиционного программного обеспечения была основана на выборке компаний, котирующихся на publiccomps.com; оценка валовой прибыли для сервисных компаний была основана на 10 000 заявок; и оценки валовой прибыли для предприятий ИИ были основаны на нескольких интервью с основателями стартапов в области ИИ.
Мнения, выраженные здесь, принадлежат отдельным лицам AH Capital Management, L.L.C. («A16z») цитируется и не является точкой зрения компании a16z или ее аффилированных лиц. Определенная информация, содержащаяся здесь, была получена из сторонних источников, в том числе от портфельных компаний фондов, находящихся под управлением a16z.Хотя a16z взят из источников, которые считаются надежными, он не проверял такую информацию независимо и не делает никаких заявлений о неизменной точности информации или ее пригодности для данной ситуации.
Этот контент предоставляется только в информационных целях, и его не следует рассматривать как юридический, деловой, инвестиционный или налоговый совет. По этим вопросам вам следует проконсультироваться со своими советниками. Ссылки на любые ценные бумаги или цифровые активы предназначены только для иллюстративных целей и не представляют собой инвестиционную рекомендацию или предложение об оказании инвестиционных консультационных услуг.Кроме того, этот контент не предназначен и не предназначен для использования какими-либо инвесторами или потенциальными инвесторами, и ни при каких обстоятельствах на него нельзя полагаться при принятии решения об инвестировании в какой-либо фонд, управляемый a16z. (Предложение инвестировать в фонд a16z будет сделано только на основании меморандума о частном размещении, соглашения о подписке и другой соответствующей документации любого такого фонда и должно быть прочитано полностью.) Любые инвестиции или портфельные компании, упомянутые, упомянутые или описанные не являются репрезентативными для всех инвестиций в автомобили, управляемые a16z, и не может быть никакой гарантии, что инвестиции будут прибыльными или что другие инвестиции, сделанные в будущем, будут иметь аналогичные характеристики или результаты.Список инвестиций, сделанных фондами, управляемыми Andreessen Horowitz (за исключением инвестиций, для которых эмитент не предоставил разрешение на публичное раскрытие a16z, а также необъявленных инвестиций в публично торгуемые цифровые активы) доступен по адресу https://a16z.com/investments /.
Приведенные здесь диаграммы и графики предназначены исключительно для информационных целей и не должны использоваться при принятии каких-либо инвестиционных решений. Прошлые показатели не свидетельствуют о будущих результатах.Содержание актуально только на указанную дату. Любые прогнозы, оценки, прогнозы, цели, перспективы и / или мнения, выраженные в этих материалах, могут быть изменены без предварительного уведомления и могут отличаться или противоречить мнениям, выраженным другими. Пожалуйста, посетите https://a16z.com/disclosures для получения дополнительной важной информации.
Что такое искусственный интеллект (ИИ)?
Искусственный интеллект – это моделирование процессов человеческого интеллекта машинами, особенно компьютерными системами.Конкретные приложения ИИ включают экспертные системы, обработку естественного языка, распознавание речи и машинное зрение.
Как работает ИИ?
По мере того, как шумиха вокруг ИИ усиливается, поставщики изо всех сил стараются продвигать то, как их продукты и услуги используют ИИ. Часто то, что они называют ИИ, является просто одним из компонентов ИИ, например, машинным обучением. ИИ требует наличия специализированного оборудования и программного обеспечения для написания и обучения алгоритмов машинного обучения. Ни один язык программирования не является синонимом ИИ, но некоторые из них, включая Python, R и Java, популярны.
В общем, системы ИИ работают, поглощая большие объемы помеченных обучающих данных, анализируя данные на предмет корреляций и шаблонов и используя эти шаблоны для прогнозирования будущих состояний. Таким образом, чат-бот, которому загружены примеры текстовых чатов, может научиться производить реалистичный обмен мнениями с людьми, или инструмент распознавания изображений может научиться определять и описывать объекты на изображениях, просматривая миллионы примеров.
ПрограммированиеAI фокусируется на трех когнитивных навыках: обучении, рассуждении и самокоррекции.
Учебные процессы. Этот аспект программирования ИИ фокусируется на сборе данных и создании правил преобразования данных в полезную информацию. Правила, которые называются алгоритмами, предоставляют вычислительным устройствам пошаговые инструкции для выполнения конкретной задачи.
Процессы рассуждений. Этот аспект программирования ИИ фокусируется на выборе правильного алгоритма для достижения желаемого результата.
Процессы самокоррекции. Этот аспект программирования ИИ предназначен для постоянной настройки алгоритмов и обеспечения максимально точных результатов.
Почему так важен искусственный интеллект?
AI важен, потому что он может дать предприятиям понимание их деятельности, о которой они, возможно, не знали ранее, и потому, что в некоторых случаях ИИ может выполнять задачи лучше, чем люди. В частности, когда дело доходит до повторяющихся, детально-ориентированных задач, таких как анализ большого количества юридических документов для обеспечения правильного заполнения соответствующих полей, инструменты искусственного интеллекта часто выполняют задания быстро и с относительно небольшим количеством ошибок.
Это способствовало резкому росту эффективности и открыло двери для совершенно новых деловых возможностей для некоторых крупных предприятий. До нынешней волны искусственного интеллекта было трудно представить себе использование компьютерного программного обеспечения для подключения водителей к такси, но сегодня благодаря этому Uber стала одной из крупнейших компаний в мире. Он использует сложные алгоритмы машинного обучения, чтобы предсказать, когда людям, вероятно, понадобятся поездки в определенных областях, что помогает заранее вывести водителей на дорогу до того, как они понадобятся.В качестве другого примера, Google стал одним из крупнейших игроков для ряда онлайн-сервисов, используя машинное обучение, чтобы понять, как люди используют их сервисы, а затем улучшить их. В 2017 году генеральный директор компании Сундар Пичаи заявил, что Google будет действовать как компания, ориентированная на ИИ.
Сегодня крупнейшие и наиболее успешные предприятия используют ИИ для улучшения своей деятельности и получения преимущества перед конкурентами.
Каковы преимущества и недостатки искусственного интеллекта?
Искусственные нейронные сети и технологии искусственного интеллекта с глубоким обучением быстро развиваются, в первую очередь потому, что ИИ обрабатывает большие объемы данных намного быстрее и делает прогнозы более точными, чем это возможно для человека.
В то время как огромный объем данных, создаваемых ежедневно, может похоронить человека-исследователя, приложения ИИ, использующие машинное обучение, могут использовать эти данные и быстро превращать их в полезную информацию. На момент написания этой статьи основным недостатком использования ИИ является дороговизна обработки больших объемов данных, необходимых для программирования ИИ.
Преимущества
- Хорошо выполняет работу, ориентированную на детали;
- Сокращение времени для задач с большим объемом данных;
- Обеспечивает стабильные результаты; и
- Виртуальные агенты на базе искусственного интеллекта всегда доступны.
Недостатки
- Дорогое удовольствие;
- Требуется глубокая техническая экспертиза;
- Ограниченное количество квалифицированных рабочих для создания инструментов искусственного интеллекта;
- Только знает, что было показано; и
- Неспособность переходить от одной задачи к другой.
Сильный ИИ против слабого ИИ
AI можно разделить на слабые и сильные.
- Слабый ИИ, также известный как узкий ИИ, – это система ИИ, разработанная и обученная для выполнения определенной задачи.Промышленные роботы и виртуальные персональные помощники, такие как Siri от Apple, используют слабый ИИ.
- Strong AI, также известный как общий искусственный интеллект (AGI), описывает программирование, которое может воспроизводить когнитивные способности человеческого мозга. Когда перед ней стоит незнакомая задача, сильная система искусственного интеллекта может использовать нечеткую логику для применения знаний из одной области в другую и автономного поиска решения. Теоретически сильная программа искусственного интеллекта должна быть способна пройти как тест Тьюринга, так и тест китайской комнаты.
Какие бывают 4 типа искусственного интеллекта?
Аренд Хинтце, доцент кафедры интегративной биологии, информатики и инженерии в Университете штата Мичиган, объяснил в статье 2016 года, что ИИ можно разделить на четыре типа, начиная с специализированных интеллектуальных систем, широко используемых сегодня, и заканчивая разумными. системы, которых еще нет. Категории следующие:
- Тип 1: реактивные машины. Эти системы искусственного интеллекта не имеют памяти и зависят от конкретной задачи. Примером может служить Deep Blue, шахматная программа IBM, победившая Гарри Каспарова в 1990-х годах. Deep Blue может определять фигуры на шахматной доске и делать прогнозы, но, поскольку у него нет памяти, он не может использовать прошлый опыт для информирования будущих.
- Тип 2: ограниченная память. У этих систем искусственного интеллекта есть память, поэтому они могут использовать прошлый опыт для принятия будущих решений. Так устроены некоторые функции принятия решений в беспилотных автомобилях.
- Тип 3: Теория разума. Теория разума – это психологический термин. Применительно к ИИ это означает, что система будет обладать социальным интеллектом, чтобы понимать эмоции. Этот тип ИИ сможет делать выводы о человеческих намерениях и предсказывать поведение, что является необходимым навыком для систем ИИ, чтобы стать неотъемлемыми членами человеческих команд.
- Тип 4: Самосознание. В этой категории системы ИИ обладают чувством «я», которое придает им осознанность.Машины с самосознанием понимают свое текущее состояние. Такого типа ИИ пока не существует.
Какие примеры технологий искусственного интеллекта и как они используются сегодня?
AI используется в различных технологиях. Вот шесть примеров:
- Автоматизация. В сочетании с технологиями искусственного интеллекта инструменты автоматизации могут расширить объем и типы выполняемых задач. Примером является автоматизация роботизированных процессов (RPA), тип программного обеспечения, которое автоматизирует повторяющиеся задачи обработки данных на основе правил, которые традиционно выполняются людьми.В сочетании с машинным обучением и новыми инструментами ИИ RPA может автоматизировать большую часть корпоративных заданий, позволяя тактическим ботам RPA передавать информацию от ИИ и реагировать на изменения процессов.
- Машинное обучение. Это наука о том, как заставить компьютер работать без программирования. Глубокое обучение – это подмножество машинного обучения, которое, говоря простым языком, можно рассматривать как автоматизацию прогнозной аналитики. Есть три типа алгоритмов машинного обучения:
- Обучение с учителем . Наборы данных помечаются, чтобы можно было обнаруживать закономерности и использовать их для маркировки новых наборов данных.
- Обучение без учителя . Наборы данных не помечены и отсортированы по сходству или различию.
- Обучение с подкреплением . Наборы данных не помечены, но после выполнения действия или нескольких действий система ИИ получает обратную связь.
- Машинное зрение. Эта технология дает машине возможность видеть.Машинное зрение фиксирует и анализирует визуальную информацию с помощью камеры, аналого-цифрового преобразования и цифровой обработки сигналов. Его часто сравнивают со зрением человека, но машинное зрение не связано биологией и может быть запрограммировано, например, видеть сквозь стены. Он используется в различных приложениях, от идентификации подписи до анализа медицинских изображений. Компьютерное зрение, сфокусированное на машинной обработке изображений, часто ассоциируется с машинным зрением.
- Обработка естественного языка (NLP). Это обработка человеческого языка компьютерной программой. Один из самых старых и наиболее известных примеров НЛП – это обнаружение спама, которое просматривает строку темы и текст электронного письма и определяет, является ли оно нежелательным. Современные подходы к НЛП основаны на машинном обучении. Задачи НЛП включают перевод текста, анализ тональности и распознавание речи.
- Робототехника. Эта область инженерии специализируется на разработке и производстве роботов. Роботы часто используются для выполнения задач, которые человеку сложно выполнять или выполнять постоянно.Например, роботы используются на сборочных линиях для производства автомобилей или НАСА для перемещения крупных объектов в космосе. Исследователи также используют машинное обучение для создания роботов, которые могут взаимодействовать в социальных сетях.
- Беспилотные автомобили. Автономные транспортные средства используют комбинацию компьютерного зрения, распознавания изображений и глубокого обучения для выработки автоматизированных навыков пилотирования транспортного средства, оставаясь на заданной полосе движения и избегая неожиданных препятствий, таких как пешеходы.
Каковы применения ИИ?
Искусственный интеллект появился на самых разных рынках. Вот девять примеров.
AI в здравоохранении. Самые большие ставки сделаны на улучшение результатов лечения пациентов и снижение затрат. Компании применяют машинное обучение, чтобы ставить более точные и быстрые диагнозы, чем люди. Одна из самых известных медицинских технологий – IBM Watson. Он понимает естественный язык и может отвечать на заданные ему вопросы.Система собирает данные о пациентах и другие доступные источники данных, чтобы сформировать гипотезу, которую затем представляет со схемой оценки достоверности. Другие приложения искусственного интеллекта включают использование онлайн-виртуальных помощников по здоровью и чат-ботов, которые помогают пациентам и клиентам здравоохранения находить медицинскую информацию, назначать встречи, понимать процесс выставления счетов и выполнять другие административные процессы. Множество технологий искусственного интеллекта также используется для прогнозирования, борьбы и понимания пандемий, таких как COVID-19.
AI в бизнесе. Алгоритмы машинного обучения интегрируются в платформы аналитики и управления взаимоотношениями с клиентами (CRM), чтобы получить информацию о том, как лучше обслуживать клиентов. Чат-боты были встроены в веб-сайты для немедленного обслуживания клиентов. Автоматизация рабочих мест также стала предметом обсуждения среди ученых и ИТ-аналитиков.
AI в образовании. AI может автоматизировать выставление оценок, давая преподавателям больше времени. Он может оценивать учащихся и адаптироваться к их потребностям, помогая им работать в своем собственном темпе.Преподаватели искусственного интеллекта могут предоставить студентам дополнительную поддержку, чтобы они не сбились с пути. И это может изменить то, где и как ученики учатся, возможно, даже заменив некоторых учителей.
AI в финансах. ИИ в приложениях для личных финансов, таких как Intuit Mint или TurboTax, разрушает финансовые учреждения. Подобные приложения собирают личные данные и предоставляют финансовые консультации. Другие программы, такие как IBM Watson, применялись в процессе покупки дома. Сегодня программное обеспечение искусственного интеллекта выполняет большую часть торговли на Уолл-стрит.
AI по закону. Процесс открытия – просеивание документов – в законодательстве часто бывает непосильным для людей. Использование ИИ для автоматизации трудоемких процессов в юридической отрасли позволяет сэкономить время и улучшить обслуживание клиентов. Юридические фирмы используют машинное обучение для описания данных и прогнозирования результатов, компьютерное зрение для классификации и извлечения информации из документов и обработку естественного языка для интерпретации запросов на информацию.
AI в производстве. Производство находится в авангарде внедрения роботов в рабочий процесс. Например, промышленные роботы, которые когда-то были запрограммированы для выполнения отдельных задач и отделены от людей-рабочих, все чаще функционируют как коботы: более мелкие, многозадачные роботы, которые взаимодействуют с людьми и берут на себя ответственность за большее количество частей работы на складах, в производственных цехах. и другие рабочие места.
AI в банковском деле. Банки успешно используют чат-ботов, чтобы информировать своих клиентов об услугах и предложениях и обрабатывать транзакции, не требующие вмешательства человека.Виртуальные помощники AI используются для улучшения и сокращения затрат на соблюдение банковских правил. Банковские организации также используют ИИ, чтобы улучшить процесс принятия решений по кредитам, установить лимиты кредита и определить инвестиционные возможности.
AI на транспорте. Помимо фундаментальной роли ИИ в управлении автономными транспортными средствами, технологии ИИ используются на транспорте для управления движением, прогнозирования задержек рейсов и повышения безопасности и эффективности морских перевозок.
Безопасность. ИИ и машинное обучение находятся в верхней части списка модных словечек, которые сегодня используют поставщики средств обеспечения безопасности, чтобы дифференцировать свои предложения. Эти термины также представляют собой действительно жизнеспособные технологии. Организации используют машинное обучение в программном обеспечении для управления информацией и событиями безопасности (SIEM) и связанных областях для обнаружения аномалий и выявления подозрительных действий, указывающих на угрозы. Анализируя данные и используя логику для выявления сходства с известным вредоносным кодом, ИИ может предоставлять оповещения о новых и возникающих атаках гораздо раньше, чем сотрудники-люди и предыдущие технологические итерации.Развивающиеся технологии играют большую роль в помощи организациям в отражении кибератак.
Расширенный интеллект против искусственного интеллекта
Некоторые отраслевые эксперты считают, что термин искусственный интеллект слишком тесно связан с популярной культурой, и это вызвало у широкой публики невероятные ожидания относительно того, как ИИ изменит рабочее место и жизнь в целом.
- Расширенный интеллект. Некоторые исследователи и маркетологи надеются, что этикетка с расширенным интеллектом , имеющая более нейтральный оттенок, поможет людям понять, что большинство реализаций ИИ будет слабым, и просто улучшит продукты и услуги.Примеры включают автоматическое отображение важной информации в отчетах бизнес-аналитики или выделение важной информации в юридических документах.
- Искусственный интеллект. Истинный ИИ, или общий искусственный интеллект, тесно связан с концепцией технологической сингулярности – будущего, управляемого искусственным суперинтеллектом, который намного превосходит способность человеческого мозга понимать его или то, как он формирует нашу реальность. Это остается в сфере научной фантастики, хотя некоторые разработчики работают над этой проблемой.Многие считают, что такие технологии, как квантовые вычисления, могут сыграть важную роль в превращении ОИИ в реальность, и что мы должны зарезервировать использование термина ИИ для этого вида общего интеллекта.
Этическое использование искусственного интеллекта
Хотя инструменты ИИ представляют ряд новых функций для бизнеса, использование искусственного интеллекта также поднимает этические вопросы, потому что, к лучшему или худшему, система ИИ укрепит то, что она уже изучила.
Это может быть проблематично, потому что алгоритмы машинного обучения, лежащие в основе многих самых передовых инструментов искусственного интеллекта, настолько умны, насколько умны данные, которые они предоставляют при обучении. Поскольку человек выбирает, какие данные используются для обучения программы искусственного интеллекта, потенциальная возможность систематической ошибки машинного обучения является неотъемлемой и должна тщательно отслеживаться.
Всем, кто хочет использовать машинное обучение как часть реальных производственных систем, необходимо учитывать этику в своих процессах обучения ИИ и стремиться избегать предвзятости.Это особенно верно при использовании алгоритмов искусственного интеллекта, которые по своей сути необъяснимы в приложениях глубокого обучения и генеративных состязательных сетей (GAN).
Объяснимость – это потенциальный камень преткновения для использования ИИ в отраслях, которые работают в соответствии со строгими нормативными требованиями. Например, финансовые учреждения в США действуют в соответствии с правилами, которые требуют от них объяснения своих решений о выдаче кредитов. Однако, когда решение об отказе в кредитовании принимается программированием ИИ, может быть трудно объяснить, как было принято решение, потому что инструменты ИИ, используемые для принятия таких решений, работают, выявляя тонкие корреляции между тысячами переменных.Когда процесс принятия решения не может быть объяснен, программа может называться ИИ черного ящика.
Эти компоненты составляют ответственное использование ИИ.Несмотря на потенциальные риски, в настоящее время существует несколько нормативных положений, регулирующих использование инструментов ИИ, а там, где законы действительно существуют, они обычно косвенно относятся к ИИ. Например, как упоминалось ранее, правила справедливого кредитования в Соединенных Штатах требуют от финансовых учреждений объяснения кредитных решений потенциальным клиентам. Это ограничивает степень, в которой кредиторы могут использовать алгоритмы глубокого обучения, которые по своей природе непрозрачны и не поддаются объяснению.
Общий регламент ЕС по защите данных (GDPR) устанавливает строгие ограничения на то, как предприятия могут использовать данные потребителей, что затрудняет обучение и функциональность многих приложений ИИ, ориентированных на потребителей.
В октябре 2016 года Национальный совет по науке и технологиям выпустил отчет, в котором рассматривалась потенциальная роль государственного регулирования в развитии ИИ, но не рекомендовалось рассматривать конкретное законодательство.
Разработать законы для регулирования ИИ будет непросто, отчасти потому, что ИИ включает в себя множество технологий, которые компании используют для разных целей, а отчасти потому, что регулирование может происходить за счет прогресса и развития ИИ.Быстрая эволюция технологий искусственного интеллекта – еще одно препятствие для формирования значимого регулирования искусственного интеллекта. Технологические прорывы и новые приложения могут мгновенно сделать существующие законы устаревшими. Например, существующие законы, регулирующие конфиденциальность разговоров и записанных разговоров, не охватывают проблему, создаваемую голосовыми помощниками, такими как Amazon Alexa и Apple Siri, которые собирают, но не распространяют разговоры, – за исключением технологических групп компаний, которые используют его для улучшения машины. алгоритмы обучения.И, конечно же, законы, которые правительствам удается разработать для регулирования ИИ, не мешают преступникам использовать эту технологию со злым умыслом.
Когнитивные вычисления и ИИ
Термины AI и когнитивные вычисления иногда используются как взаимозаменяемые, но, вообще говоря, термин AI используется по отношению к машинам, которые заменяют человеческий интеллект, моделируя то, как мы воспринимаем, обучаемся, обрабатываем и реагируем на информацию в окружающей среде. .
Обозначение «когнитивные вычисления» используется в отношении продуктов и услуг, которые имитируют и улучшают процессы мышления человека.
Какова история искусственного интеллекта?
Идея о неодушевленных предметах, наделенных разумом, существует с древних времен. Греческий бог Гефест изображался в мифах как выковывающий роботов-слуг из золота. Инженеры в Древнем Египте построили статуи богов, оживляемых священниками. На протяжении веков мыслители от Аристотеля до испанского теолога XIII века Рамона Лулля и Рене Декарта и Томаса Байеса использовали инструменты и логику своего времени для описания человеческих мыслительных процессов как символов, заложив основу таких концепций искусственного интеллекта, как представление общих знаний.
Поддержка современной области искусственного интеллекта, с 1956 г. по настоящее время.Конец 19-го и первая половина 20-го веков породили фундаментальную работу, которая положила начало современному компьютеру. В 1836 году математик Кембриджского университета Чарльз Бэббидж и Августа Ада Байрон, графиня Лавлейс, изобрели первую конструкцию программируемой машины.
1940-е гг. Математик из Принстона Джон фон Нейман придумал архитектуру компьютера с хранимой программой – идею о том, что компьютерная программа и данные, которые она обрабатывает, могут храниться в памяти компьютера .А Уоррен Маккалок и Уолтер Питтс заложили основу нейронных сетей.
1950-е гг. С появлением современных компьютеров ученые смогли проверить свои идеи о машинном интеллекте. Один из методов определения наличия у компьютера интеллекта был разработан британским математиком и взломщиком кодов времен Второй мировой войны Аланом Тьюрингом. Тест Тьюринга сосредоточился на способности компьютера обмануть следователей, заставив поверить, что его ответы на их вопросы были сделаны человеком.
1956. Считается, что современная область искусственного интеллекта началась в этом году во время летней конференции в Дартмутском колледже. В конференции, спонсируемой Агентством перспективных оборонных исследовательских проектов (DARPA), приняли участие 10 корифеев в этой области, в том числе пионеры искусственного интеллекта Марвин Мински, Оливер Селфридж и Джон Маккарти, которому приписывают введение термина искусственный интеллект . Также присутствовали Аллен Ньюэлл, ученый-компьютерщик, и Герберт А.Саймон, экономист, политолог и когнитивный психолог, представил свою новаторскую программу Logic Theorist, компьютерную программу, способную доказывать определенные математические теоремы и названную первой программой ИИ.
1950-х и 1960-х годов. После конференции Дартмутского колледжа лидеры молодой области искусственного интеллекта предсказали, что искусственный интеллект, эквивалентный человеческому мозгу, не за горами, что получит серьезную поддержку со стороны правительства и промышленности.Действительно, почти 20 лет хорошо финансируемых фундаментальных исследований привели к значительному прогрессу в области ИИ: например, в конце 1950-х годов Ньюэлл и Саймон опубликовали алгоритм решения общих проблем (GPS), который не решал сложных проблем, но заложил основы для разработка более сложных когнитивных архитектур; Маккарти разработал Lisp, язык программирования ИИ, который используется до сих пор. В середине 1960-х профессор Массачусетского технологического института Джозеф Вайценбаум разработал ELIZA, раннюю программу обработки естественного языка, которая заложила основу для сегодняшних чат-ботов.
1970-е и 1980-е годы. Но достижение общего искусственного интеллекта оказалось неуловимым, не неизбежным, ему мешали ограничения компьютерной обработки и памяти, а также сложность проблемы. Правительство и корпорации отказались от поддержки исследований искусственного интеллекта, что привело к периоду бездействия, который длился с 1974 по 1980 год и был известен как первая «зима искусственного интеллекта». В 1980-х годах исследования методов глубокого обучения и внедрение в отрасли экспертных систем Эдварда Фейгенбаума вызвали новую волну энтузиазма в области ИИ, за которой последовал еще один крах государственного финансирования и поддержки отрасли.Вторая зима AI продлилась до середины 1990-х годов.
1990-е годы по сегодняшний день. Увеличение вычислительной мощности и всплеск данных вызвали в конце 1990-х годов возрождение искусственного интеллекта, которое продолжается и по сей день. Последнее внимание к ИИ привело к прорыву в обработке естественного языка, компьютерном зрении, робототехнике, машинном обучении, глубоком обучении и многом другом. Более того, ИИ становится все более осязаемым, приводя в движение автомобили, диагностируя болезни и укрепляя свою роль в массовой культуре.В 1997 году Deep Blue от IBM победил российского гроссмейстера Гарри Каспарова, став первой компьютерной программой, победившей чемпиона мира по шахматам. Четырнадцать лет спустя компания IBM Watson очаровала публику, когда победила двух бывших чемпионов на игровом шоу Jeopardy !. Совсем недавно историческое поражение 18-кратного чемпиона мира по Го Ли Седола от AlphaGo из Google DeepMind ошеломило сообщество Го и стало важной вехой в развитии интеллектуальных машин.
AI как услуга
Поскольку затраты на оборудование, программное обеспечение и персонал для ИИ могут быть высокими, многие поставщики включают компоненты ИИ в свои стандартные предложения или предоставляют доступ к платформам «искусственный интеллект как услуга» (AIaaS).AIaaS позволяет отдельным лицам и компаниям экспериментировать с ИИ для различных бизнес-целей и пробовать различные платформы, прежде чем брать на себя обязательства.
Популярные облачные предложения AI включают следующее:
9 замечательных приложений для математической практики
Автор Juned Ghanchi
Мобильные приложения становятся все более полезными инструментами для учащихся и учителей, обеспечивая образовательную ценность для учащихся всех классов и возрастов. Одна из предметных областей, которая больше всего выиграла от этого распространения, – это математика.Но как выбрать одно из, казалось бы, бесконечного моря математических приложений? Вот 9 отличных вариантов, которые помогут разобраться с вариантами.
1. Классная математика
Это отличное приложение для студентов, которые могут попрактиковаться и получить навыки базовой математики. Приложение, как следует из названия, поставляется с интерфейсом, предлагающим классную доску для занятий математикой.
Он помогает детям быстро усвоить все основные математические факты, относящиеся к сложению, вычитанию, умножению и делению.Он генерирует математические упражнения в двух разных режимах: режиме ответов и режиме карточек. В то время как первый позволяет вводить ответы и получать обратную связь, второй позволяет отвечать устно. Приложение изначально было бесплатным, а сейчас его цена в App Store составляет 0,99 доллара США.
2. Суши-монстр
Вы хотите абсолютно бесплатное математическое приложение с надежным интерфейсом и простыми в использовании методиками для детей? Что ж, у Sushi Monster есть игривый интерфейс и персонажи, которые помогут детям расширить свои математические навыки и знания.
Приложение предлагает 12 различных уровней игры, включая 7 уровней для сложения и 5 различных уровней для умножения. Тарелки суши с соответствующими номерами шеф-повар ставит на прилавок. Игрок составляет правильную комбинацию чисел на тарелках и пытается достичь целевого числа, которое несет суши-монстр. Если комбинация чисел правильная, суши съедает монстр. Каждый раунд, состоящий из 14 целевых чисел, создает увлекательный способ работы с числами.
3. Moose Math
Хотите, чтобы ваш ребенок учился сложению, счету, вычитанию, геометрии и сортировке забавным и увлекательным способом? Moose Math может быть именно тем, что вы ищете. Приложение решает почти все основные математические задачи в увлекательной игровой форме, которая быстро увлекает учащегося.
По сути, это игровое приложение из забавных персонажей, известное как Dust Funnies. Эти персонажи на разных этапах помогут детям справиться с различными типами математических задач.Когда вы выходите победителем на одном этапе, на другом открывается другой набор проблем.
4. Алгебра DragonBox 5+
Это приложение, которое может помочь детям развить навыки решения задач и алгебры с разными уровнями сложности. Он предлагает очень интуитивно понятный интерфейс, который упрощает использование, с разными уровнями, соответствующими навыкам учащегося.
Приложение, которое поддерживает педагогическую структуру вместе с забавным интерфейсом, также может быть идеальным для учителей.Приложение поставляется в двух версиях: одна для детей от 5 до 8 лет, а другая – для детей от 12 лет.
5. Reflex
Среди всех перечисленных здесь приложений для беглости математики Reflex выделяется основанной на исследованиях системой изучения математики для учащихся в возрасте от 2 до 8 лет.
Он предлагает адаптивную среду обучения, создающую объемы изучения математики для студентов с разным уровнем способностей. Предлагать учащимся задачи в соответствии с их уровнем навыков интуитивно понятно.
6. Бесплатный графический калькулятор
Это еще одно замечательное приложение с интуитивно понятным и удобным интерфейсом, которое больше работает как инструмент для выполнения сложных вычислений.Это приложение может быть лучшим другом для студентов, которые хотят овладеть расчетами, но оно менее полезно для обучения математике.
Это простое приложение впечатляет широким набором инструментов для разнообразных математических действий. С помощью того же приложения вы получите научный и графический калькулятор, конвертер единиц, инструмент статистики и хороший справочник по всем необходимым формулам, константам и другой важной информации.
7. Математика операций
Если вам нужно приложение, которое позволяет очень легко изучать и практиковать математику, то это то, что вам нужно.Он предлагает очень простой для понимания пользовательский интерфейс, в котором все четко объяснено и доступно. Приложение также поставляется с очень удобной поддержкой для учащихся.
Operation Math уникален тем, что создает увлекательный игровой интерфейс со 105 заданиями на время, позволяя детям изучать и практиковать все математические действия, включая сложение, вычитание, деление и умножение. Идеально ориентированный на детей 9-11 лет, он предлагает увлекательный способ взаимодействия с числами и вычислениями.Его стоит покупать по цене 2,99 доллара для iOS и 1,99 доллара для Android, чтобы улучшить математические способности вашего ребенка.
8. Стойка номерная
Number Rack – еще одно красивое приложение, которое поможет детям научиться использовать числа и осваивать их наглядно. Предлагая подвижные цветные бусинки, приложение побуждает учащихся группировать и сортировать их, а в процессе – изучать сложение и вычитание.
Это увлекательное математическое приложение, идеально подходящее для детей начального уровня. Он предлагает учебные модули для разных уровней навыков и поставляется с текстовыми инструментами для написания уравнений.
9. Пройдите через математику
Это невероятно увлекательное приложение для iOS для беглости математики, в котором рассказывание историй помогает юным ученикам со временем развить математические навыки. Используя очень интерактивный пользовательский интерфейс, он предлагает три разных уровня игры с числами, чтобы помочь детям научиться сложению, вычитанию, умножению и делению.
Помимо базовых математических навыков, приложение также помогает с уравнениями сложения, уравнениями вычитания, уравнениями умножения, двухступенчатыми уравнениями и некоторыми другими относительно продвинутыми математическими фактами.Приложение, созданное в пиратской тематике, даже имеет веселую фоновую музыку и стреляет пушечными ядрами!
Эти приложения могут быть отличным и интересным способом помочь вашим детям выучить математику. Думаешь, я что-то пропустил в этом списке? Добавьте их в раздел комментариев ниже!
Дополнительные полезные математические ресурсы см .:
Джунед Ганчи – генеральный директор IndianAppDevelopers.
.